dom lizarraga
POOD Session 2: Test Driving Shameless Green
Session 2: Considering Existing Tests and Meet the Open/Closed Principle
Date: August 16, 2025
This blog post consists in four parts:
- My notes on Test Driving Shameless Green
- My notes on code Open/Closed principle”
- My notes on code Code smells talk”
- A Google NotebookLM link that contains 2 exercises based on the code smells video (quiz and flashcards).
Key Concepts
- Aim for code that is easier to understand, then refactor.
- Single responsabillity principle (SRP)
- How adding conditionals increases code paths exponentially.
- Tolerate duplication as a temporary tradeoff for clarity.
- Recognizing code smells
- The 24 code smells (and 2 more!)
- Open/Closed principle
- Refactor systematically by discarding and solving one at a time
Test Driving Shameless Green
In this lesson, our main task was to watch Sandi Metz’s talk, study her code, and then answer six questions about it. Afterward, we turned to the book 99 Bottles to compare our answers with Sandi’s own.
The real challenge, however, wasn’t just about finding the “right” answer, it was about learning how to justify our decisions. Could we explain our reasoning clearly enough to convince other programmers that our solution (or Sandi’s) was the better one? Working in a team of three, we debated each approach and practiced the art of defending design choices.
- What decisions must be made before you can write this first test?
I think what behavior should we test. Is it a number that adds another number? Is it a boolean? In this case is a concatenated string.
Also, what methods should be publicly available? What is the API look like? (Bearing in mind that we should name methods after the concept they represent rather than how they currently behave.)
What parameters are we going to allow? And what method for?
Maybe, which test to write first: entire song, multiple verses, or single verse? (Think in simplicity)
Arrange, Act, Assert
We shouldn’t overthink these decisions initially
- Is it better to interpolate ‘number’ or to add a conditional?
I think we should aim for understability first, therefore the conditional may be a good start.
Once we deepen our domain understanding we can provide more flexibility with the interpolation.
Sandi’s suggestion was to interpolate over conditional. As the test gets more specific the code will become more general.
- Why not just interpolate a conditional?
The code we are writing is the following:
class Bottles
def verse(number)
"#{number} bottles of beer on the wall, " +
"#{number} bottles of beer. \n" +
"Take one down and pass it around, " +
"#{number - 1} botle#{"s" if number - != 1} of beer on the wall.\n"
end
end
I think this version is hard to understand at a glance, you gotta read it more than once and remembering that the code you write is many times read than written, I point to understability first.
Sandi proposed a case statement where the verses are almost identical but vary by the “number” variable. Again, it’s much simpler and easier to follow.
- Why is duplication in #verse acceptable, but not in #verses?
I think because of the Single Responsibility principle, if we add duplication in #verses we are mixing tasks between those methods. One if for returning one verse at once and the other is for passing the “number” variable as iteration.
- What should the expectation in the song test be?
The song method is the main subject of this exercise, and i think of it as the final result of the code so even when it seems tedious, writing down all the 99 verses is the way to test that code is working properly.
class Bottles
def song
verses(99, 0)
end
def verses(upper, lower)
upper.downto(lower).map { |i| verse(i) }.join("\n")
end
def verse(number)
case number
when 0
"No more bottles of beer on the wall, no more bottles of beer.\nGo to the store and buy some more, 99 bottles of beer on the wall.\n"
when 1
"1 bottle of beer on the wall, 1 bottle of beer.\nTake it down and pass it around, no more bottles of beer on the wall.\n"
when 2
"2 bottles of beer on the wall, 2 bottles of beer.\nTake one down and pass it around, 1 bottle of beer on the wall.\n"
else
"#{number} bottles of beer on the wall, #{number} bottles of beer.\nTake one down and pass it around, #{number-1} bottles of beer on the wall.\n"
end
end
end
- What design flaw forces you to write this last annoying test?
The flaw is that song does not accept any arguments, it always produces the full song from 99 to 0. The song method is closed to extension.
— Quiz answers —
> What decisions must be made before you can write this first test? (Video 1:55)
> You have to make lots of decisions! For example, you must design your API, decide on the classes you plan to create and the messages to which they respond, and determine the required inputs and expected outputs for each method.
> (99 Bottles book section 2.2)
> Is it better to interpolate 'number' or to add a conditional? (Video 2:50)
> It is better to interpolate the value of the number into the verse string rather than to add a new conditional.
> (99 Bottles book section 2.2)
> We tend to discount the complexity of adding a conditional where none existed before, but beware!
> A method containing a single two-branch conditional has two execution paths, that is, there are two separate paths through the code.
> If you add a second two-branch conditional, you create four possible execution paths.
> Adding yet another two-branch conditional (now you have three two-branch conditionals) results in eight execution paths, not six.
> The number of execution paths increases exponentially, calculated as the number of branches raised to the power of the number of conditionals.
> For example, 2 branches × 10 conditionals = 1,023 possible paths!
> There's no way a method like this has a complete test suite.
> Why not just interpolate a conditional?!? (Video 4:08)
> Interpolating a conditional to decide whether or not to add an 's' to "bottle" adds complexity without creating a useful abstraction. It's better to duplicate for now and wait for more information from future tests.
> Refactor only when you are confident about your abstractions. Until then, tolerate duplication as a temporary tradeoff for clarity.
> (99 Bottles book section 2.2)
> Why is duplication in #verse acceptable, but not in #verses? (Video 6:24)
> The Single Responsibility Principle says each method should do one thing well. The #verse method’s job is to produce correct lyrics. The #verses method’s job is to call #verse for each verse and join the results.
> Duplication inside #verse is fine because it’s encapsulated — it’s invisible to other parts of the app. But duplicating that logic elsewhere (like in #verses) would violate SRP.
> (99 Bottles book section 2.6)
> What should the expectation in the song test be? (Video 7:44)
> The whole song.
> (99 Bottles book section 2.10)
> The song test is annoying! You're forced to write that long expectation because of a design flaw in the code. Speculate about what that flaw might be. (Video 9:45)
> This was just to make you think! The answer will become clear as the course progresses. :-)
Meet the Open/Closed Principle
Block 3 covers two new ideas: the Open/Closed Principle and Code Smells. Here, we were tasked to watch short videos (~4 mins) that showed us design principles for the next code exercise.
Watch #1: Listening to Change
What we do most of us do for a living is, we change code. And what that means is the cost of code is in the reading.
Writing code happens only once, but reading happens over and over and over.
Have you ever done that thing where you’re working on some code and you add code for a feature that’s not yet been asked for but that you guess will arrive in the future? How’d that turn out? Dead code, whether it’s obsolete or anticipatory, adds costs, if the cost of code is in the reading.
That last note remineded me of this Jeremy Smith tweet
Things I’ve learned the hard way about web development:
- automated testing is always worth it in the long-run
- limit your dependencies where possible, and keep up with dependency upgrades
- don’t write code in anticipation of future needs
- integrate code changes often, no long feature branches
- deploy schema, data, and code changes separately whenever possible
- limit your work in progress
- make sure you have monitoring in place so that, when things go wrong, you know about it first
- don’t save the toughest, most unclear part of a project for last
- if you think you might miss a deadline, communicate that as early as possible
- address common production exceptions so you don’t lose important rare ones in the noise
- anticipate product usage changes and seasonality and account for it in infrastructure changes and feature releases
The rule is: the sum of the costs incurred by guessing far outweighs the money you save by very occasionally being right. So what should you do? The rule is every bit of code you write should be for a feature that is currently being used.
Here is the challenge: Every place, the song currently says six bottles, it should instead say 1 six-pack.
We could fulfill this new requirement by adding two more branches to the existing case statement but that would lead to 4 branches and eventually to unmaintainable code.
Things that change, do. And what I mean by that is that the stuff that changes, the things that change at the highest rate in your application often are concepts or ideas that are core to your domain. And so the most changeable things are the most valuable to your business.
We need to make it more amenable to change, which means we need OO.
Watch #2: Starting With the Open/Closed Principle
Requirement is: change the word from “six bottles” to “1 six-pack”. We gotta make the code open. Open is the “O” in SOLID.
This principle says that when you’re adding code to fulfill a new requirement, you should not simultaneously change existing code.
Think of it, what it would mean for your code, if every time you went to write the code to fulfill a new requirement, the existing code was open to the new code you wanted to write. This will imply:
- Tests continue to run green
- Almost impossible to break and existing feature
- You can write brand new tests
- Implement new feature by just adding code. Not adjusting current code.
Diagram for checking if code is open:
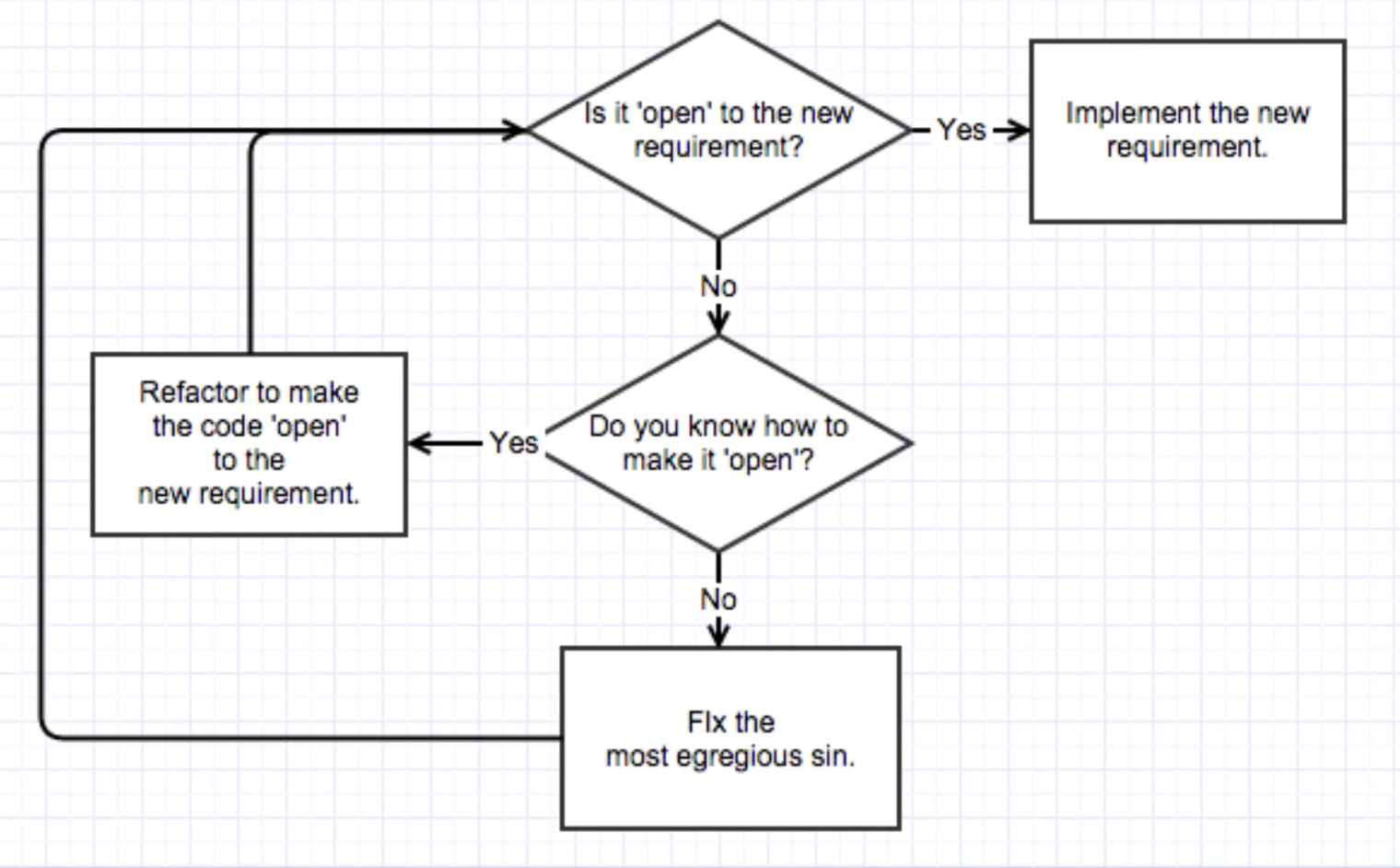
A very strict definition of openness for this problem. The current code is open to new requirement if you can implement that requirement without changing anything in any existing class.
Do you know how to make it open? if you can’t instantly describe the transformation that will bend this code into a shape that’s open to the new requirement, you don’t really know how to do it. (This is very common)
We need a technique to find code smells that we’ll see in the next section.
Watch #3: Recognizing Code Smells
Have you ever been defeated by refactoring? You try and make a change, and you dive in and change a bunch of code, and you break a bunch of tests, and you thrash around with a machete, you finally throw up your hands and do a git reset --hard?
Why? Because code has a lots of different wrong parts.
If you try to fix everything at once is easy to get really in over you head.
It would be much easier to improve code if you could reach in and grab a single thread and tug and fix that one piece until it was correct, leaving everything else unchanged.
Code smells are things that might be wrong with your code. They’re the names of code arrangements that could be a problem.
They are 24, listed in the book (chapter 3), Martin Fowler’s refactoring.
Code smelss categories (5):
| Bloaters - Things that increase code volume unnecessarily | |
| Long Function | Self explanatory |
| Large Class | Self explanatory |
| Data Clumps | Two or more pieces of data that always come together should be wrapped in an object |
| Long Parameter List | Self explanatory |
| Primitive Obsession | Passing primitives (String, Integer) around with behavior instead of wrapping them in objects |
| Abusers - Things you could do in OO but should be careful with | |
| Repeated Switches | Same conditional pattern appearing multiple times `case statements`; branches should be objects |
| Refused Bequest | Subclasses that don't implement all superclass methods and throw exceptions (related to inheritance) |
| Alternative Classes with Different Interfaces | Different classes doing the same thing with different method names |
| Temporary Field | Using temporary variables to cache results or name operations; consider using methods |
| Global Data | Data you don't own that others can change |
| Mutable Data | Prefer immutable objects when possible |
| Preventers - Code that prevents easy changes | |
| Divergent Change | One object changes for different reasons; should be split into multiple objects |
| Shotgun Surgery | One single change requires modifications in many places; should be consolidated |
| Mysterious Name | Self explanatory |
| Dispensables - Arbitrary additions that increase length without adding value | |
| Lazy Element (lazy class) | Object not doing enough to justify its existence |
| Speculative Generality | Writing code for imagined requirements; when you write code for future features |
| Data Class | Class with only data; behavior should be combined with data |
| Duplicated Code | Self explanatory |
| Comments | Explaining code instead of writing self-explanatory code |
| Loops | Use Map/Filter instead of writing loops |
| Couplers - Objects bound together by messages | |
| Feature Envy | Object interacting too much with another object; may belong together |
| Insider Trading | Objects passing private implementation details |
| Message Chains | Sending messages through multiple objects in sequence (Message.where(sender: "Joe").count("OK")) |
| Middle Man | Object only forwarding messages without adding value |
Code smells map to curative refactorings.
Each of those refactorings comes with a recipe, a step-by-step guide about how to do it. you can identify code smells, then go look up the refactoring recipes that are curative for it, select one, and then follow the step-by-step directions to get rid of that smell.
Refactoring is to alter the arrangement of code without changing its behavior. (refactoring should happen all under green because tests ought your back)
Watch #4: Identifying the Best Point of Attack
Requirement is: change the word from “six bottles” to “1 six-pack”.
class Bottles
def song
verses(99, 0)
end
def verses(upper, lower)
upper.downto(lower).map { |i| verse(i) }.join("\n")
end
def verse(number)
case number
when 0
"No more bottles of beer on the wall, no more bottles of beer.\nGo to the store and buy some more, 99 bottles of beer on the wall.\n"
when 1
"1 bottle of beer on the wall, 1 bottle of beer.\nTake it down and pass it around, no more bottles of beer on the wall.\n"
when 2
"2 bottles of beer on the wall, 2 bottles of beer.\nTake one down and pass it around, 1 bottle of beer on the wall.\n"
else
"#{number} bottles of beer on the wall, #{number} bottles of beer.\nTake one down and pass it around, #{number-1} bottles of beer on the wall.\n"
end
end
end
We have repeated switches, duplicated code, long function, maginc number (have meaning but lack fo name), and concealed concept (duplication of concepts that are represented by different implementations of code).
We have at least 5 code smells and we gotta choose just one. And probably discard some of the code smells as candidates, since it’s common that some code smells create other code smells.
We throw out long function and repeated switches. that leaves magic number, concealed concept and duplicated code.
We’ll tackle concealed concept. The core idea here is that, if we isolate the thing we want to vary, it’s then possible to make new variants without editing existing code. And that’s what it means to be open.
Watch #5: Refactoring Systematically
You can think of refactoring versus adding new features as two different programming modes.
-
In refactoring mode, you move code around, but you don’t touch a test. The test run merrily along unchanged, and you should never see red.
-
In adding new features mode, the first thing you do is write a failing test; you should see red right away. Then you can write the code to make that test pass.
-
And if the code base you’re working on is open to your new feature, then you can implement that feature without altering any existing code.
When refactoring tests break:
-
You’re not really refactoring. You’re not rearranging code without changing behavior. You’re actually rearranging code while changing behavior.
-
The tests are flawed. Tests are tightly coupled to current implementation of the code.
Notes on Sandi Metz’s talk (Get a Whiff of This (code smells talk)”):
-
Kent Beck created the term “code smells” and with Martin Fowler, both wrote the chapter 3 of the book Refactoring.
-
They have been in this since 1990.
-
Try to mention 5 code smells? Most people can’t.
-
Once you give a complex idea a name, we can talk to each other in an unambiguous way without having miscommunications.
-
A code smells might indicate a problem, not that it is a problem.
-
Sandi lists the 5 categories of code smells, bloaters, abusers, code change preventers, dispensables and couplers— they can be found above in a table.
-
If ugly code doesn’t change then it cost no money.
-
In OO we have data + behaviour in objects, not only data.
-
Don’t write code that you think will be needed later. Don’t guess! The times you are right have to outweight the time you’re wrong.
-
The code is written once and read thousands therefore we cost money reading code. Make it clear
-
If you add the code smell speculative generality you increase levels of abstraction, which is indirection in turn difficult to understand.
-
Every code smell maps to its own curative refactoring recipe
-
The next PDF includes a cross reference of Martin Fowler refactoring to each code smell
Code smells Talk exercises Google NotebookLM
In the following link you’ll find 50 flashcards and a 10 questions-quiz based on Sandi’s video “Get a Whiff of This (code smells)”
It’s a Google NotebookLM link to exercise
Hope you can learn something new !
Here is an sample how the flashcards look like and my result of the exercises:
Flashcards on Get a Whiff of This by Sandi Metz (code smells) talk:
Get a Whiff of This by Sandi Metz (code smells) talk quiz result: