dom lizarraga
I read Effective testing with RSpec by Myron Marston and Ian Dees. on April 11, 2025
Review
Recently, I participated in a very competitive interview. When I submitted the code challenge, I felt my weakest area was the testing suite. Even though feedback was not available, being honest with myself and seeing some posts from the reviewers, I decided to dive deeper into testing.
I picked up books like Professional Rails Testing by Jason Swett, Hands-On Test Driven Development by Greg Donald, Effective Testing with RSpec by Myron Marston and Ian Dees and even attended a testing workshop by Lucian Ghinda.
I had practiced testing before, but I felt it was time to level up and get it closer to the same standard as the rest of my code.
Here are the notes, examples, and quotes that stood out to me while reading.
- Getting started with RSpec.
- From writing specs to running them.
- The RSpec way.
- Starting On the Outside: Acceptance Specs.
- Testing in isolation: Unit specs.
- Getting real: Integration specs.
- Structuring code examples.
- Slicing and dicing specs with metadata.
- Configuring RSpec.
- Exploring RSpec expectations.
- Matchers included in RSpec expectations.
- Creating custom matchers.
- Understanding test doubles.
Part I — Chapter 1. Getting Started.
Picture of the book!
Where should i put this testing heuristics Given-When-Then scenarios
The forward is written by Tom Stewart author of Understanding Computation And he expresses something that picked my curiosity:
After all, the big challenge of test-driven development is not knowing how to write tests, but knowing how to listen to them. For your tests to be worth the bites they are written in, they must be able to speak to you about how well the underlying program is designed and implemented and, crucially, you must be able to hear them. The words and ideas baked into RSpec are carefully chosen to heighten your sensitivity to this kind of feedback. As you play with its expressive little pieces you will develop a test for what a good test looks like, and the occasional stumble over a test that now seems harder or uglier or way more annoying than necessary will start you on a journey of discovery that leads to a better design for that part of your code base.”
In the introduction we see different quotes like our tests are broken again! Why does the suite take so long to run? What value are we getting from this test anyway? No matter whether you are new to automated tests or helping using them for years, this book will help you write more effective tests. by effective, we mean tests that give you more value than the time spent writing them.
This book you will learn RSpec in three phases:
Part I: Introductory exercises to get you acquainted with respect Part II: A work example spanning several chapters, so that you can see RSpecin action on a meaningful sized project Part III-V: A series of deep dives into specific aspects of RSpec, which will have you get the most out of RSpec
RSpec and behavior driven development:
RSpec bills itself as a Behavior Driven Development (BDD) test framework. I would like to take a moment to talk about our use of that term, along with the related term, Test Driven Development (TDD).
With TDD, you write each test case just before implementing the next bit of behavior. When you have a well written test, you wind up with more maintainable code. you can make changes with the confidence that your test suite will let you know if you have broken something.
It is about the way they enable fearless improvements to your design.
BDD brings the emphasis to where it is supposed to be: your code’s behavior.
RSpec is a productive Ruby test framework. we say productive because everything about it, its style, api, libraries, and settings are designed to support you as you write great software.
We have a specific definition of effective here, does this test pay for the cost of writing and running it? A good test will provide at least one of these benefits:
-
design guidance: helping you distill all those fantastic ideas in your head into running, maintainable code
-
safety net: finding errors in your code before your customers do
-
documentation:capturing the behavior of a working system to help it’s maintainers
As you follow along through the examples in this book, you will practice several habits that will help you test effectively:
When you describe precisely what you want your program to do, you avoid being too strict ( and failing when an irrelevant detail changes) or too lax (and getting false Confidence from incomplete tests).
By writing your specs to report failure at the right level of detail, you give just enough information to find the cause of the problem, without drawing in excessive output.
By clearly separating essential test code from noisy setup code, you communicate what’s exactly expected of the application, and you avoid repeating unnecessary detail.
When you reorder, profile, and filter your specs, you unearth order dependencies, slow tests and incomplete work.
Installing RSpec.
It is made of three independent ruby gems:
rspec-core: is the overall test harness that runs your specs.
rspec-expectations: provides a readable, powerful Syntax for checking properties of your code.
rspec-mocks: makes it easy to isolate the code you are testing from the rest of the system.
➜ rspec-book rbenv local 3.4.2
➜ rspec-book rbenv rehash
➜ rspec-book ruby -v
ruby 3.4.2 (2025-02-15 revision d2930f8e7a) +PRISM [arm64-darwin24]
➜ rspec-book bundle init
Writing new Gemfile to /Users/dominiclizarraga/code/dominiclizarraga/rspec-book/Gemfile
➜ rspec-book bundle add rspec
Fetching gem metadata from https://rubygems.org/...
Resolving dependencies...
Fetching gem metadata from https://rubygems.org/.
Fetching diff-lcs 1.6.2
Fetching rspec-support 3.13.4
Installing rspec-support 3.13.4
Installing diff-lcs 1.6.2
Fetching rspec-core 3.13.4
Fetching rspec-expectations 3.13.5
Fetching rspec-mocks 3.13.5
Installing rspec-core 3.13.4
Installing rspec-expectations 3.13.5
Installing rspec-mocks 3.13.5
Fetching rspec 3.13.1
Installing rspec 3.13.1
Note: The book suggests to use gem install rspec however I think it’s important to remember that, that command will install the library globally to that Ruby version so if you want to avoid that and narrow the impact that this installation may have, I suggest to create its own directory and use bundle init which will create a Gemfile and then you can add rspec gem to the Gemfile or use bundle add rspec. This will set this rspec version only to this project.
Let’s write our first spec 😁
The book starts with the very simple example of building a sandwich. What’s the most important property of a sandwich? the bread? the condiments? No, the most important thing about a sandwich is that it should taste good.
RSpec uses the words describe a it to express concepts in a conversational format:
- “Describe an ideal sandwich”
- “First, it is delicious”
01-getting-started/01/spec/sandwich_spec.rb
RSpec.describe “An ideal sandwich” do
it “is delicious” do
# developers work this way with RSpec all the time; they start with an outline and fill it in as they go.
end
end
Then let’s add the classes and methods
01-getting-started/01/spec/sandwich_spec.rb
RSpec.describe “An ideal sandwich” do
it “is delicious” do
sandwich = sandwich.new(“it’s delicious”, [])
taste = sandwich.taste
expect(sandwich). to eq(“it’s delicious”)
end
end
This file defines your test, known in RSpec as your specs, short for a specification (because they specify the desired behavior of your code). The outer describe block creates an example group – an example group defines what you are testing, in this case, a sandwich, and keeps related specs together.
The nested block, the one beginning with it, is an example of the sandwich’s use. As you write specs, you will tend to keep each example focused on one particular size of behavior you are testing.
This first paragraphs reminds me of Jason Swett’s book on how many times he stresses to the readers that tests are a specifications not validations! I was able to count at least 8 times that he mentions that for example: A specification is a statement of how some aspect of a software product should behave. Remember that testing is about a specification, not verification. A test suite is a structured collection of behavior specifications.
Differences between tests, specs and examples:
• A test validates that a bit of code is working properly. • A spec describes the desired behavior of a bit of code. • An example shows how a particular API is intended to be used.
In the bits of code that we wrote we can clearly see the pattern arrange/act/assert.
The last line with the expect keyword is the assertion in other test frameworks. Let’s look at the RSpec methods we’ve used:
• RSpec.describe creates an example group (set of related tests).
• it creates an example (individual test).
• expect verifies an expected outcome (assertion).
Up to this point this spec serves two purposes: documenting what your sandwich should do and checking that the sandwich does what it is supposed to. (Lovely, isn’t it? 🤌)
Let’s run the test and see what happens. (We’ll start reading common error tests)
$ ➜ rspec-book git:(master) ✗ bundle exec rspec 01-getting-started/01/spec/sandwich_spec.rb
F
Failures:
1) An ideal sandwich is delicious
Failure/Error: sandwich = Sandwich.new("delicious", [])
NameError:
uninitialized constant Sandwich
# ./01-getting-started/01/spec/sandwich_spec.rb:8:in 'block (2 levels) in <top (required)>'
Finished in 0.00539 seconds (files took 0.09368 seconds to load)
1 example, 1 failure
Failed examples:
rspec ./01-getting-started/01/spec/sandwich_spec.rb:6 # An ideal sandwich is delicious
Here we can see that RSpec gives us a detailed report showing us the line of code where the error occurred, and the description of the problem, in this case sandwich has not been initialized.
With this we are following Red/Green/Refactor development practice essential to TDD and BDD. With this workflow, you’ll make sure each example catches failing or missing code before you implement the behavior you’re testing.
The next step after writing a failing spec is to make it pass.
# add to the top of the file
`Sandwich = Struct.new(:taste, :toppings)` # more about [Structs official docs](https://rubyapi.org/3.4/o/struct) and [Stackoverflow](https://stackoverflow.com/questions/25873672/ruby-class-vs-struct)
# re-run the tests
You should see now a green dot “.” and 0 failures
➜ rspec-book git:(master) ✗ bundle exec rspec 01-getting-started/01/spec/sandwich_spec.rb
.
Finished in 0.00578 seconds (files took 0.07271 seconds to load)
1 example, 0 failures
Let’s add a second spec!
Sandwich = Struct.new(:taste, :toppings)
RSpec.describe "An ideal sandwich" do
it "is delicious" do
# Developers work this way with RSpec all the time; they start with an outline and fill it in as they go
sandwich = Sandwich.new("delicious", [])
taste = sandwich.taste
expect(taste).to eq("delicious")
end
it "lets me add toppings" do
# Developers work this way with RSpec all the time; they start with an outline and fill it in as they go
sandwich = Sandwich.new("delicious", [])
sandwich.toppings << "cheese"
toppings = sandwich.toppings
expect(toppings).not_to be_empty
end
end
This example shows 2 new features, check for falsehood (using .not_to instead of .to) and check for data structure attributes
But also they are repetitive, let’s introduce 3 new RSpec features:
• RSpec hooks run automatically at specific times during testing.
• Helper methods are regular Ruby methods; you control when these run.
• RSpec’s let construct initializes data on demand.
To avoid the repetitiveness that the prior code shows, let’s start using what we described previously hooks, helper methods, let.
Hooks
The first thing that we will try in our test Suite is a before hook, which will run automatically before each example. (it reminds me to ActiveRecord callbacks)
RSpec.describe "An ideal sandwich" do
before { @sandwich = Sandwich.new("delicious", []) }
it "is delicious" do
taste = @sandwich.taste
expect(taste).to eq("delicious")
end
it "lets me add toppings" do
@sandwich.toppings << "cheese"
toppings = @sandwich.toppings
expect(toppings).not_to be_empty
end
end
The setup code is shared across specs, but the individual Sandwich instance is not. Every example gets its own sandwich. That means that you can add toppings as you do in the second spec, with the confidence that the changes won’t affect other examples.
Let’s try a different approach. (a more traditional Ruby approach)
RSpec does a lot for us; it is easy to forget that it is just playing Ruby underneath. Each example group is a ruby class, which means that we can define methods on it.
RSpec.describe "An ideal sandwich" do
def sandwich
@sandwich ||= Sandwich.new("delicious", [])
end
it "is delicious" do
taste = sandwich.taste
expect(taste).to eq("delicious")
end
it "lets me add toppings" do
sandwich.toppings << "cheese"
toppings = sandwich.toppings
expect(toppings).not_to be_empty
end
end
A typical Ruby implementation might look something like the one we just wrote which uses memoization.
This pattern is pretty easy to find in Ruby but it is not without its pitfalls. the ||= operator works by seeing if @sandwich is falsey, that is, false or nil, before creating a new @sandwich. That means that it won’t work if we are actually trying to store something falsey.
Sharing objects with let
RSpec gives us an alternative construct, let. Which handles the edge case that we previously discussed with memoization.
You can think of let as assigning a name — in this case, :sandwich — to the result of a block. This block is lazily evaluated, meaning RSpec will only run it the first time :sandwich is accessed within an example. The result is then memoized (cached) for the remainder of that example.
Our recommendation is to use these code-sharing techniques where they improve maintainability, lesson noise, and increase clarity.
RSpec.describe "An ideal sandwich" do
let (:sandwich) { Sandwich.new("delicious", []) } # [let official docs](https://rspec.info/features/3-13/rspec-core/helper-methods/let/)
it "is delicious" do
taste = sandwich.taste
expect(taste).to eq("delicious")
end
it "lets me add toppings" do
sandwich.toppings << "cheese"
toppings = sandwich.toppings
expect(toppings).not_to be_empty
end
end
At the end of the chapter there is a “Your turn” section where the author encouraged you to respond a couple of questions and for the first chapter they asked the following: Which of the three ways to reduce duplication that we have shown to you do you like the best for this example? Why? Can you think of situations where the others might be a better option?
As all good engineering questions it depends as we have seen the first one which was the before hook, it is very clean, it reads good however we saw that it has some drawbacks, like it would return nil if the instance variable is misspelled and all the refactor gymnastics that it implies for refactoring just one file even when the instance variable is not used in a group example. Then the helper method has the memoization problem and finally they let alternative covers those issues.
Some extra coding for solidifying let knowledge:
RSpec.describe "An ideal sandwich" do
let(:sandwich) { Sandwich.new("delicious", []) }
it "is delicious" do
puts "Example 1 - Sandwich object_id: #{sandwich.object_id}"
# Example 1 - Sandwich object_id: 1232
taste = sandwich.taste
expect(taste).to eq("delicious")
end
it "lets me add toppings" do
puts "Example 2 - Sandwich object_id: #{sandwich.object_id}"
# Example 2 - Sandwich object_id: 1240
sandwich.toppings << "cheese"
toppings = sandwich.toppings
expect(toppings).not_to be_empty
end
end
# within same group example
it "uses the same object within one example" do
puts "First call: #{sandwich.object_id}"
# First call: 1248
sandwich.toppings << "cheese"
puts "Second call: #{sandwich.object_id}" # Same object!
# Second call: 1248
expect(sandwich.toppings).to include("cheese") # Cheese is still there
end
A recap of Chapter 1: We explored the describe block, which is called on a group of examples, and the it block, which is called an example (or a test case in some other testing frameworks). We covered the expect keyword. We also looked at the Arrange-Act-Assert pattern. We thoroughly read through test failures and what they mean.
We understood that testing serves two purposes: documenting what the code should do, and checking that the code does what it’s supposed to do. We explored how to negate an expectation, and how to test collections such as arrays and hashes. Finally, we saw three different ways of reducing code in tests: hooks, Ruby helper methods, and the let construct.
Part I — Chapter 2. From writing specs to running them.
# Add the next file 01-getting-started/01/spec/coffee_spec.rb
class Coffee
def ingridients
@ingridients ||= []
end
def add(ingridient)
ingridients << ingridient
end
def price
1.00
end
end
RSpec.describe "A cup of coffee" do
let(:coffee) { Coffee.new }
it "costs $1" do
expect(coffee.price).to eq(1)
end
context "with milk" do
before { coffee.add :milk }
it "costs $1.25" do
expect(coffee.price).to eq(1.25)
end
end
end
And in this chapter we explore the --format documentation
➜ rspec-book git:(master) bundle exec rspec 01-getting-started/01 --format documentation
A cup of coffee
costs $1
with milk
costs $1.25 (FAILED - 1)
An ideal sandwich
is delicious
lets me add toppings
Failures:
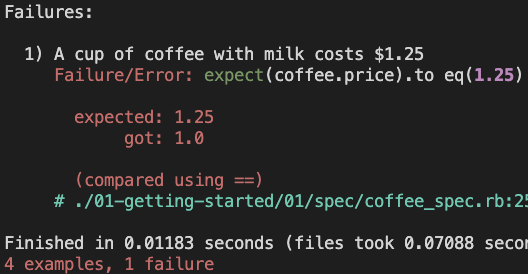
1) A cup of coffee with milk costs $1.25
Failure/Error: expect(coffee.price).to eq(1.25)
expected: 1.25
got: 1.0
(compared using ==)
# ./01-getting-started/01/spec/coffee_spec.rb:25:in 'block (3 levels) in <top (required)>'
Finished in 0.01762 seconds (files took 0.08827 seconds to load)
4 examples, 1 failure
Failed examples:
rspec ./01-getting-started/01/spec/coffee_spec.rb:24 # A cup of coffee with milk costs $1.25
Another suggestion from the book is adding the gem coderay which highlights with different colors the line that is failing. This is particularly useful when dealing with complex tests suites.
bundle exec rspec 01-getting-started/01 -fd (see the expect and 1.25)
Another tool that is shown in this chapter is how to identify a slow test by adding --profile n (n is the number of offenders we’d like to see)
# 01-getting-started/01/spec/slow_spec.rb
RSpec.describe "The sleep() method" do
it("can sleep for 0.1 seconds") { sleep 0.1 }
it("can sleep for 0.2 seconds") { sleep 0.2 }
it("can sleep for 0.3 seconds") { sleep 0.3 }
it("can sleep for 0.4 seconds") { sleep 0.4 }
it("can sleep for 0.5 seconds") { sleep 0.5 }
end
# $ bundle exec rspec 01-getting-started/01 -fd --profile 2
The sleep() method
can sleep for 0.1 seconds
can sleep for 0.2 seconds
can sleep for 0.3 seconds
can sleep for 0.4 seconds
can sleep for 0.5 seconds
Top 2 slowest examples (0.90852 seconds, 58.8% of total time):
The sleep() method can sleep for 0.5 seconds
0.50321 seconds ./01-getting-started/01/spec/slow_spec.rb:6
The sleep() method can sleep for 0.4 seconds
0.40531 seconds ./01-getting-started/01/spec/slow_spec.rb:5
Finished in 1.54 seconds (files took 0.0894 seconds to load)
5 examples, 0 failures
Also this chapter covers how to run specific tests when you don’t need to run the whole test suite (from directories, to files to even just examples).
$ rspec spec/unit/specific_spec.rb # Load just one spec file
$ rspec spec/unit spec/foo_spec.rb # Or mix and match files and directories
Example for running examples that contains word “milk” (searches are case-sensitive)
$ bundle exec rspec 01-getting-started/01 -e milk -fd
Run options: include {full_description: /milk/}
A cup of coffee
with milk
costs $1.25 (FAILED - 1)
Failures:
1) A cup of coffee with milk costs $1.25
Failure/Error: expect(coffee.price).to eq(1.25)
expected: 1.25
got: 1.0
(compared using ==)
# ./01-getting-started/01/spec/coffee_spec.rb:25:in 'block (3 levels) in <top (required)>'
Finished in 0.0128 seconds (files took 0.06799 seconds to load)
1 example, 1 failure
And if you need to run only one example or test case, you can pass rspec 01-getting-started/01/spec/coffee_spec.rb:25 and RSpec will run the example that starts on that line.
Rerunning Everything That Failed
There is one RSpec command that allows you to run just exactly the failing specs, this is pretty useful as the last command because you avoid running the whole test suite and you can fix one spec, rerun it, fix the next one and so on let’s dive in
# here we can see that same error is being brought up, example: `with milk costs $1.25`
➜ rspec-book git:(master) ✗ bundle exec rspec 01-getting-started/01/
.F.......
Failures:
1) A cup of coffee with milk costs $1.25
Failure/Error: expect(coffee.price).to eq(1.25)
expected: 1.25
got: 1.0
(compared using ==)
# ./01-getting-started/01/spec/coffee_spec.rb:29:in 'block (3 levels) in <top (required)>'
Finished in 1.55 seconds (files took 0.08332 seconds to load)
9 examples, 1 failure
Failed examples:
rspec ./01-getting-started/01/spec/coffee_spec.rb:28 # A cup of coffee with milk costs $1.25
Then we add the command --only-failures at the end and this will ask us for a path to write the last run diagnosis, in this case we added:
➜ rspec-book git:(master) ✗ bundle exec rspec 01-getting-started/01/ --only-failures
To use `--only-failures`, you must first set `config.example_status_persistence_file_path`.
# add this config line
RSpec.configure do |config|
config.example_status_persistence_file_path = 'spec/examples.txt'
end
Which will add a spec/examples.txt file with details as the following:
| example_id | status | run_time |
|---|---|---|
| ./01-getting-started/01/spec/coffee_spec.rb[1:1] | passed | 0.00064 seconds |
| ./01-getting-started/01/spec/coffee_spec.rb[1:2:1] | failed | 0.01486 seconds |
| ./01-getting-started/01/spec/sandwich_spec.rb[1:1] | passed | 0.00007 seconds |
| ./01-getting-started/01/spec/sandwich_spec.rb[1:2] | passed | 0.00163 seconds |
| ./01-getting-started/01/spec/slow_spec.rb[1:1] | passed | 0.10517 seconds |
| ./01-getting-started/01/spec/slow_spec.rb[1:2] | passed | 0.20549 seconds |
| ./01-getting-started/01/spec/slow_spec.rb[1:3] | passed | 0.30431 seconds |
| ./01-getting-started/01/spec/slow_spec.rb[1:4] | passed | 0.40278 seconds |
| ./01-getting-started/01/spec/slow_spec.rb[1:5] | passed | 0.50561 seconds |
Finally, when we re-run the --only-failures it will search for that “failed status” and run only that one! You can see it below:
➜ rspec-book git:(master) ✗ bundle exec rspec 01-getting-started/01/ --only-failures
Run options: include {last_run_status: "failed"} 👈
F
Failures:
1) A cup of coffee with milk costs $1.25
Failure/Error: expect(coffee.price).to eq(1.25)
expected: 1.25
got: 1.0
(compared using ==)
# ./01-getting-started/01/spec/coffee_spec.rb:29:in 'block (3 levels) in <top (required)>'
Finished in 0.01276 seconds (files took 0.08701 seconds to load)
1 example, 1 failure
Failed examples:
rspec ./01-getting-started/01/spec/coffee_spec.rb:28 # A cup of coffee with milk costs $1.25
The usage of command rspec –next-failure
rspec-book git:(master) ✗ bundle exec rspec 02-running-specs
# above command created spec/tea_examples.txt
example_id | status | run_time |
----------------------------------- | ------ | --------------- |
./02-running-specs/tea_spec.rb[1:1] | failed | 0.0001 seconds |
./02-running-specs/tea_spec.rb[1:2] | failed | 0.00005 seconds |
02-running-specs/tea_spec.rb
class Tea
end
RSpec.configure do |config|
config.example_status_persistence_file_path = 'spec/tea_examples.txt'
end
RSpec.describe "Tea" do
let(:tea) { Tea.new }
it "tastes like Earl Grey" do
expect(tea.flavor).to be :earl_grey
end
it "is hot" do
expect(tea.temperature).to be > 200.0
end
end
➜ rspec-book git:(master) ✗ bundle exec rspec 02-running-specs
FF
Failures:
1) Tea tastes like Earl Grey
Failure/Error: expect(tea.flavor).to be :earl_grey
NoMethodError:
undefined method 'flavor' for an instance of Tea
# ./02-running-specs/tea_spec.rb:11:in 'block (2 levels) in <top (required)>'
2) Tea is hot
Failure/Error: expect(tea.temperature).to be > 200.0
NoMethodError:
undefined method 'temperature' for an instance of Tea
# ./02-running-specs/tea_spec.rb:15:in 'block (2 levels) in <top (required)>'
Finished in 0.00362 seconds (files took 0.08398 seconds to load)
2 examples, 2 failures
Failed examples:
rspec ./02-running-specs/tea_spec.rb:10 # Tea tastes like Earl Grey
rspec ./02-running-specs/tea_spec.rb:14 # Tea is hot
Then we add the option –next-failure and it will only run the very next failure, not the whole test suite.
$ bundle exec rspec 02-running-specs --next-failure
Run options: include {last_run_status: "failed"}
F
Failures:
1) Tea tastes like Earl Grey
Failure/Error: expect(tea.flavor).to be :earl_grey
NoMethodError:
undefined method 'flavor' for an instance of Tea
# ./02-running-specs/tea_spec.rb:11:in 'block (2 levels) in <top (required)>'
Finished in 0.00049 seconds (files took 0.08649 seconds to load)
1 example, 1 failure
Failed examples:
rspec ./02-running-specs/tea_spec.rb:10 # Tea tastes like Earl Grey
This chapter focused on how specs should look and how they can be run.
It began with the introduction of the context block, which is an alias for describe. However, it has a more specific and useful purpose: it’s often used for phrases that describe a particular state or condition of the object being tested.
We learned about the command rspec --format documentation or --f d, which separates group examples from individual examples and adds indentation to visually show nesting—such as one or two levels deep.
We also explored the gem called coderay, which adds color to test output, making it easier to scan for failures. Additionally, we covered the command rspec --profile 2, which helps identify the slowest-running tests.
Next, we learned about the rspec --example word command, which allows us to run only the group examples or examples that match the given word.
Then, we explored how to run a specific test by including the line number in the command, like so:
rspec ./spec/coffee_spec.rb:25.
We also discovered a very useful command: rspec --only-failures. This runs only the tests that failed in the previous run by using a file that stores the status of each example.
We then looked into running tests in focused mode—allowing us to run only specific context, it, or describe blocks by tagging them. We can assign custom tags and then pass those tags when running rspec to filter the examples accordingly.
Another feature we explored was how to sketch out the test suite when you have more ideas in mind than time to implement them. You can use an it block with just a description (without a body), which RSpec treats as pending. You can also mark tests as incomplete using pending, skip, or xit.
Finally, we covered the --next-failure command, which runs only the next failing test from the previous run.
| Command | Description |
|---|---|
| rspec –format documentation | Displays test output with indentation to show nesting of examples. |
| rspec –profile 2 | Shows the 2 slowest-running tests to help identify performance bottlenecks. |
| rspec –example word | Runs only the examples that match the given word. |
| rspec ./spec/filename_spec.rb:25 | Runs only the test located on line 25 of the specified file. |
| rspec –only-failures | Runs only the tests that failed in the previous run. |
| rspec –next-failure | Runs the next failing test from the last run. |
Part I — Chapter 3. The RSpec Way.
All these prior features of RSpec are designed to make certain habits easy: • Writing examples that clearly spell out the expected behavior of the code • Separating common setup code from the actual test logic • Focusing on just what you need to do to make the next spec pass
Writing specs isn’t the goal of using RSpec—it’s the benefits those specs provide. Let’s talk about those benefits now; they’re not all as obvious as “specs catch bugs.”
- Specs increase confidence in your project • The “happy path” through a particular bit of code behaves the way you want it to. • A method detects and reacts to an error condition you’re anticipating. • That last feature you added didn’t break the existing ones. • You’re making measurable progress through the project.
- Eliminating fear
- With broad test coverage, developers find out early if new code is breaking existing features.
- Enabling refactoring
- Without a good set of specs, refactoring is a daunting task.
- Our challenge as developers is to structure our projects so that big changes are easy and predictable. As Kent Beck says, “for each desired change, make the change easy (warning: this may be hard), then make the easy change.”
- Guiding design
- If you write your specs before your implementation, you’ll be your own first client.
- As counterintuitive as it may sound, one of the purposes of writing specs is to cause pain—or rather, to make poorly designed code painful.
- Sustainability
- RSpec may slow initial development but ensures faster, safer future changes—unless the project is small, static, or disposable.
- Documenting behavior.
- Transforming your workflow
- Each run of your suite is an experiment you’ve designed in order to validate (or refute) a hypothesis about how the code behaves.
- You get fast, frequent feedback when something doesn’t work, and you can change course immediately
Running the entire suite Consider the difference between a test suite taking 12 seconds and one taking 10 minutes. After 1,000 runs, the former has taken 3 hours and 20 minutes. The latter has cumulatively taken nearly 7 days.
Deciding what not to test Every behavior you specify in a test is another point of coupling between your tests and your project code. That means you’ll have one more thing you’ll have to fix if you ever need to change your implementation’s behavior.
If you do need to drive a UI from automated tests, try to test in terms of your problem domain (“log in as an administrator”) rather than implementation details (“type admin@example.com into the third text field”).
Another key place to show restraint is the level of detail in your test assertions. Rather than asserting that an error message exactly matches a particular string (“Could not find user with ID 123”), consider using substrings to match just the key parts (“Could not find user”). Likewise, don’t specify the exact order of a collection unless the order is important.
Part II — Building an app with RSpec.
Part II — Chapter 4. Building an App With RSpec.
In this chapter authors decide to build an expense tracker app where users can add/search expenses.
It will use Sinatra as router and not rails since we don’t need background workers, mailers, views, asset pipelie and so on.
We need a small JSON APIs and Sinatra will do the job.
Acceptance specs => which checks the behavior of the application as a whole. By the end of the chapter, we’ll have the skeleton of a live app and a spec to test it (It makes me think like a smoke check for the core flow.)
Also, we used a “outside-in development” which means start working at outermost layer (the HTTP request/response cycle) and work your way inward to the classes and methods that contain the logic.
Create a directory and add bundler
# 04-acceptance-specs/
# add ENV['RACK_ENV'] = 'test' to spec_helper.rb
# add bundler as package manager
`bundle init`
# then in the Gemfile file add the next gems
gem "rspec", "~> 3.13"
gem "coderay" # easy-to-read, syntax-highlighted
gem 'rack-test' # provide an API for tests
gem 'sinatra' # implement the web application
# then run `bundle install` and `bundle exec rspec --init`, which will create:
`.rspec` # contains rspec command line flags
`spec/spec_helper.rb` # contains configuration options
It’s easy to feel overwhelmed as we’re deciding what to test first. Where do we start?
What’s thecore of the project? What’s the one thing we agree our API should do? It should faithfully save the expenses we record.
We’re only going to use two of the most basic features of HTTP in these examples:
• A GET request reads data from the app.
• A POST request modifies data.
First testing run 🏃
require 'rack/test'
require 'json'
module ExpenseTracker
RSpec.describe 'Expense Tracker API' do
include Rack::Test::Methods
it 'records submitted expenses' do
coffee = {
'payee' => 'Starbucks',
'amount' => 5.75,
'date' => '2025-06-10'
}
post '/expenses', JSON.generate(coffee) # This will simulate an HTTP POST request (it's a Rack::Test helper)
end
end
end
In the console we run bundle exec rspec 04-acceptance-specs/01/expense_tracker/spec/expense_tracker_api_spec.rb and we get the next error:
F
Failures:
1) Expense Tracker API records submitted expenses
Failure/Error: post '/expenses', JSON.generate(coffee)
NameError:
undefined local variable or method 'app' for #<RSpec::ExampleGroups::ExpenseTrackerAPI:0x000000011e93b538>
# ./04-acceptance-specs/01/expense_tracker/spec/expense_tracker_api_spec.rb:14:in 'block (2 levels) in <module:ExpenseTracker>'
Finished in 0.00161 seconds (files took 0.15436 seconds to load)
1 example, 1 failure
Failed examples:
rspec ./04-acceptance-specs/01/expense_tracker/spec/expense_tracker_api_spec.rb:8 # Expense Tracker API records submitted expenses
Given error tells us that we cannot use app because we have not defined it yet, so let’s add it (temporaly with a ruby helper method.)
# 04-acceptance-specs/01/expense_tracker/spec/expense_tracker_api_spec.rb
def app
ExpenseTracker::API.new
end
it 'records submitted expenses' do
...
end
# 04-acceptance-specs/01/expense_tracker/app/api.rb
require 'sinatra/base'
require 'json'
module ExpenseTracker
class API < Sinatra::Base # This class defines the barest skeleton of a Sinatra app.
end
end
Now, by adding ExpenseTracker::API and the app method we’re verifying only that the POST request completes without crashing the app.
Let’s check the response
F
Failures:
1) Expense Tracker API records submitted expenses
Failure/Error: expect(last_response.status).to eq(200)
expected: 200
got: 404
(compared using ==)
# ./04-acceptance-specs/01/expense_tracker/spec/expense_tracker_api_spec.rb:21:in 'block (2 levels) in <module:ExpenseTracker>'
Finished in 0.02102 seconds (files took 0.20637 seconds to load)
1 example, 1 failure
We need to add the route for this:
# 04-acceptance-specs/01/expense_tracker/app/api.rb
post '/expenses' do
end
Let’s fill the body of the response, we start from the testing, in this case parsing the response
# 04-acceptance-specs/01/expense_tracker/spec/expense_tracker_api_spec.rb
it 'records submitted expenses' do
coffee = {
'payee' => 'Starbucks',
'amount' => 5.75,
'date' => '2017-06-10'
}
post '/expenses', JSON.generate(coffee)
p last_response
expect(last_response.status).to eq(200)
parsed = JSON.parse(last_response.body) 👈
expect(parsed).to include('expense_id' => a_kind_of(Integer)) 👈
end
Then in our API we are going to fool the response with the following:
# 04-acceptance-specs/01/expense_tracker/app/api.rb
post '/expenses' do
JSON.generate('expense_id' => 42)
end
And as we’re inspecting the last_response we can see the @body contains the hash with key as expense_id and value as 42.
-specs/01/expense_tracker/spec/expense_tracker_api_spec.rb
#<Rack::MockResponse:0x000000011db1ba48 @original_headers={"content-type" => "text/html;charset=utf-8", "content-length" => "17", "x-xss-protection" => "1; mode=block", "x-content-type-options" => "nosniff", "x-frame-options" => "SAMEORIGIN"}, @errors="", @status=200, @headers={"content-type" => "text/html;charset=utf-8", "content-length" => "17", "x-xss-protection" => "1; mode=block", "x-content-type-options" => "nosniff", "x-frame-options" => "SAMEORIGIN"}, @writer=#<Method: Rack::MockResponse(Rack::Response::Helpers)#append(chunk) /Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rack-3.1.16/lib/rack/response.rb:359>, @block=nil, @body=["{\"expense_id\":42}"], @buffered=true, @length=17, @cookies={}>
Saving expenses is all fine and good, but it’d be nice to retrieve them. Let’s fetch expenses by date.
Let’s start by adding more expenses:
# within the example 'records submitted expenses' add these 2 hashes
it 'records submitted expenses' do
zoo = post_expense(
'payee' => 'Zoo',
'amount' => 15.25,
'date' => '2017-06-10'
)
groceries = post_expense(
'payee' => 'Whole Foods',
'amount' => 95.20,
'date' => '2017-06-11'
)
coffee = post_expense(
'payee' => 'Starbucks',
'amount' => 5.75,
'date' => '2017-06-10'
)
get '/expenses/2017-06-10'
expect(last_response.status).to eq(200)
expenses = JSON.parse(last_response.body)
expect(expenses).to contain_exactly(coffee, zoo)
end
And as you may see we added the post_expense(expense) method, so add it within describe block:
def post_expense(expense)
post '/expenses', JSON.generate(expense)
expect(last_response.status).to eq(200)
parsed = JSON.parse(last_response.body)
expect(parsed).to include('expense_id' => a_kind_of(Integer))
expense.merge('id' => parsed['expense_id'])
end
When you run the test suite bundle exec rspec 04-acceptance-specs/01/expense_tracker/spec/expense_tracker_api_spec.rb you should see an error like this:
Failures:
1) Expense Tracker API records submitted expenses
Failure/Error: expect(expenses).to contain_exactly(coffee, zoo)
expected collection contained: [{"amount" => 5.75, "date" => "2017-06-10", "id" => 42, "payee" => "Starbucks"}, {"amount" => 15.25, "date" => "2017-06-10", "id" => 42, "payee" => "Zoo"}]
actual collection contained: []
the missing elements were: [{"amount" => 5.75, "date" => "2017-06-10", "id" => 42, "payee" => "Starbucks"}, {"amount" => 15.25, "date" => "2017-06-10", "id" => 42, "payee" => "Zoo"}]
# ./04-acceptance-specs/01/expense_tracker/spec/expense_tracker_api_spec.rb:47:in 'block (2 levels) in <module:ExpenseTracker>'
Finished in 0.0305 seconds (files took 0.2402 seconds to load)
1 example, 1 failure
And the API endpoint we should enable is the following (GET '/expenses/:date')
# 04-acceptance-specs/01/expense_tracker/app/api.rb
module ExpenseTracker
class API < Sinatra::Base
post '/expenses' do
JSON.generate('expense_id' => 42)
end
get '/expenses/:date' do
JSON.generate([])
end
end
end
Now, we can mark the test_case as pending by adding right after the it block pending 'Need to persist expenses' this will change the red color from our terminal to a more friendly yellow.
And with this warning we can add a webserver gem, in this case add gem 'rackup', gem 'webrick' to Gemfile and create a file:
# 04-acceptance-specs/01/expense_tracker/config.ru # new file 🚨
require_relative 'app/api'
run ExpenseTracker::API.new
# run `cd 04-acceptance-specs/01/expense_tracker` and from that directory [NOT rspec-book] run `bundle exec rackup`
# this will boot up a webserver
➜ expense_tracker git:(master) ✗ bundle exec rackup
[2025-07-23 14:29:17] INFO WEBrick 1.9.1
[2025-07-23 14:29:17] INFO ruby 3.4.2 (2025-02-15) [arm64-darwin24]
[2025-07-23 14:29:17] INFO WEBrick::HTTPServer#start: pid=6213 port=9292
::1 - - [23/Jul/2025:14:29:59 -0400] "GET /expenses/2017-06-10 HTTP/1.1" 200 2 0.0063
In another terminal you can try out your server with the following command:
➜ rspec-book git:(master) ✗ curl localhost:9292/expenses/2017-06-10 -w "\n"
[] # this is due to our 04-acceptance-specs/01/expense_tracker/app/api.rb GET route ✅
To recap of this chapter we began a project about tracking expenses that will register and search them, with only 2 actions. We set up bundler since we need more libraries than RSpec, such as Sinatra, SQlite, Rack, WEBrick, etc.
We started with an outside-in approach where we defined the outer layer of the app in this case the POST endpoint. We were encouraged to think deeply about the public API and what type of data we wanted back as a response. Then we started building the classes, and we made progress by clearing one error at a time. We used two new matchers include, a_kind_of and contain_exactly which we didn’t use but was mentioned and lastly we refactored an method for persisting a Hash of expenses and booted up the web server with bundle exec rackup. It’s important to mention that all these requests are simulated.
Part II — Chapter 5. Testing in isolation: Unit specs.
In this chapter we’re going to be picking up where we left off: the HTTP routing layer.
Unit tests typically involve isolating a class or method from the rest of the code. The result is faster tests and easier-to-find errors.
We’ll use unit spec to refer to the fastest, most isolated set of tests for a particular project.
With the unit tests in this chapter, you won’t be calling methods on the API class directly. Instead, you’ll still be simulating HTTP requests through the Rack::Test interface. Xavier Shay article about how he tests rails apps
Your tests for any particular layer—from customer-facing code down to low-level model classes—should drive that layer’s public API. You’ll find yourself making more careful decisions about what does or doesn’t go into the API.
The behavior we want to see is - what happens when an API call succeeds and when it fails.
# create a file spec/unit/app/api_spec.rb
require_relative '../app/api'
module ExpenseTracker
RSpec.describe API do
describe 'POST /expenses' do
context 'when the expense is successfully recorded' do
it 'returns the expense id'
it 'responds with a 200 (OK)'
end
context 'when the expense fails validation' do
it 'returns an error message'
it 'responds with a 422 (Unprocessable entity)'
end
end
end
end
Hit the console with bundle exec rspec 04-acceptance-specs/01/expense_tracker/app/api_spec.rb all tests should appear as “pending”.
We are still modeling the API so we want something like this:
result = @ledger.record({ 'some' => 'data' })
result.success? # => a Boolean
result.expense_id # => a number
result.error_message # => a string or nil
Remember, we’re testing the API class, not the behavior.
This is the perfect spot for test doubles. A test double is an object that stands in for another one during a test.
To create a stand-in for an instance of a particular class, you’ll use RSpec’s instance_double method, and pass it the name of the class you’re imitating. Martin Fowler’s article about test double
Add the follwoing code to file 04-acceptance-specs/01/expense_tracker/spec/unit/api_spec.rb
require_relative '../app/api'
require 'rack/test'
module ExpenseTracker
RecordResult = Struct.new(:success?, :expense_id, :error_message)
RSpec.describe API do
include Rack::Test::Methods
def app
API.new(ledger: ledger)
end
let(:ledger) { instance_double('ExpenseTracker::Ledger') }
describe 'POST /expenses' do
context 'when the expense is successfully recorded' do
it 'returns the expense id'
it 'responds with a 200 (OK)'
end
context 'when the expense fails validation' do
it 'returns an error message'
it 'responds with a 422 (Unprocessable entity)'
end
end
end
end
As with the acceptance specs, you’ll be using Rack::Test to route HTTP requests to the API class. Eventually, we’ll move the RecordResult class into the codebase.
The seam between layers is where integration bugs hide. Using a simple value object like a RecordResult or Struct between layers makes it easier to isolate code and trust your tests. Article related to catching bugs between layers.
🔦 If you feel a bit lost here is a summary of the 3 files we have written in chapter 5. 🔎
api.rb: Defines a thin HTTP API (Sinatra app). It’s the boundary/interface between the outside world and your app logic.
-
Parse incoming HTTP requests
-
Forward them to your application logic (Ledger object)
-
Return an HTTP response (JSON with status codes)
It’s like a router/controller in Rails.
api_spec.rb: Tests the API in isolation using test doubles, to control its behavior and avoid hitting the database or real logic.
This is a unit test for your API layer.
You’re using an instance_double of Ledger to isolate the API layer and check:
-
Does the API route call ledger.record?
-
Does it return the expected response if ledger.record is successful?
-
What happens if ledger.record fails?
expense_tracker_spec.rb: Acceptance-level (end-to-end) spec. It tests the whole system, using real logic (no doubles), to ensure the full behavior works.
-
It sends POST requests with expense data.
-
It sends a GET request to retrieve expenses for a given day.
-
It checks whether the correct data is returned.
-
It tests the full stack: HTTP → Sinatra → Ledger → persistence.
initialize(ledger:): Adds “dependency injection” so the API can be wired up with either real objects (in end-to-end tests) or test doubles (in unit tests).
# 04-acceptance-specs/01/expense_tracker/spec/unit/api_spec.rb
require_relative '../../app/api'
require 'rack/test'
module ExpenseTracker
RecordResult = Struct.new(:success?, :expense_id, :error_message)
RSpec.describe API do
include Rack::Test::Methods
def app
API.new(ledger: ledger)
end
let(:ledger) { instance_double('ExpenseTracker::Ledger') }
describe 'POST /expenses' do
context 'when the expense is successfully recorded' do
it 'returns the expense id' do
expense = { 'some' => 'data' }
allow(ledger).to receive(:record)
.with(expense)
.and_return(RecordResult.new(true, 417, nil))
post '/expenses', JSON.generate(expense)
parsed = JSON.parse(last_response.body)
expect(parsed).to include('expense_id' => 417)
end
it 'responds with a 200 (OK)'
end
context 'when the expense fails validation' do
it 'returns an error message'
it 'responds with a 422 (Unprocessable entity)'
end
end
end
end
The allow method configures the test double’s behavior: when the call in this case the API class invokes .record the double will return a new RecordResult instance.
Also, please notice that the expense hash doesn’t contain real data, this is ok since the whole point of the Ledger test double is that it will return a canned success or failure response.
If we run the test at this point we get the following:
Failures:
1) ExpenseTracker::API POST /expenses when the expense is successfully recorded returns the expense id
Failure/Error: expect(parsed).to include('expense_id' => 417)
expected {"expense_id" => 42} to include {"expense_id" => 417}
Diff:
@@ -1 +1 @@
-"expense_id" => 417,
+"expense_id" => 42,
# ./04-acceptance-specs/01/expense_tracker/spec/unit/api_spec.rb:27:in 'block (4 levels) in <module:ExpenseTracker>'
Top 4 slowest examples (0.03167 seconds, 91.4% of total time):
...
Let’s handle success and failure of the request in the api.rb
# 04-acceptance-specs/01/expense_tracker/app/api.rb
require 'sinatra/base'
require 'json'
require_relative 'ledger'
module ExpenseTracker
class API < Sinatra::Base
def initialize(ledger: Ledger.new)
@ledger = ledger
super()
end
post '/expenses' do
request.body.rewind
expense = JSON.parse(request.body.read)
result = @ledger.record(expense)
if result.success?
JSON.generate('expense_id' => result.expense_id)
else
status 422
JSON.generate('error' => result.error_message)
end
end
end
end
# 04-acceptance-specs/01/expense_tracker/spec/unit/api_spec.rb
require_relative '../../app/api'
require 'rack/test'
module ExpenseTracker
RSpec.describe API do
include Rack::Test::Methods
def app
API.new(ledger: ledger)
end
let(:ledger) { instance_double('ExpenseTracker::Ledger') }
describe 'POST /expenses' do
context 'when the expense is successfully recorded' do
let(:expense) { { 'some' => 'data' } }
before do
allow(ledger).to receive(:record)
.with(expense)
.and_return(RecordResult.new(true, 417, nil))
end
it 'returns the expense id' do
post '/expenses', JSON.generate(expense)
parsed = JSON.parse(last_response.body)
expect(parsed).to include('expense_id' => 417)
end
it 'responds with a 200 (OK)' do
post '/expenses', JSON.generate(expense)
expect(last_response.status).to eq(200)
end
end
context 'when the expense fails validation' do
let(:expense) { { 'some' => 'data' } }
before do
allow(ledger).to receive(:record)
.with(expense)
.and_return(RecordResult.new(false, 417, "Expense incomplete"))
end
it 'returns an error message' do
post '/expenses', JSON.generate(expense)
parsed = JSON.parse(last_response.body)
expect(parsed).to include('error' => 'Expense incomplete')
end
it 'responds with a 422 (Unprocessable entity)' do
post '/expenses', JSON.generate(expense)
expect(last_response.status).to eq(422)
end
end
end
end
end
The last excersice is to add GET /expenses/:date starting from writing down tests:
- Write the
describeblock, then thecontext, theitblocks. - The
API::Sinatrais already working (we have not defined the storage engine yet) - Add
instance_doubleofledger(RecordResultis no longer needed) - Add the method
expenses_on(date)on theLedgerclass. - Generate a sample data of the JSON we want as return. (The hash should contain amount, date and payee)
- Modify the
api.rbsince theGETroute always return empty array. It shoudl handle success and failure too.
Here is the api.rb and the api_spec.rb. These refactored specs report “just the facts” of the expected behavior.
# 04-acceptance-specs/01/expense_tracker/app/api.rb
get '/expenses/:date' do
date = params[:date]
unless /\A\d{4}-\d{2}-\d{2}\z/.match?(date)
status 400
return JSON.generate({ error: "Invalid date format" })
end
expenses = @ledger.expenses_on(date)
if expenses.any?
JSON.generate(expenses)
else
JSON.generate([])
end
end
# 04-acceptance-specs/01/expense_tracker/spec/unit/api_spec.rb
module ExpenseTracker
RSpec.describe API do
include Rack::Test::Methods
def app
API.new(ledger: ledger)
end
let(:ledger) { instance_double('ExpenseTracker::Ledger') }
describe "GET /expenses/:date" do
context "when expenses exist on given date" do
let(:expense_canned_response) { [ {"amount" => 5.50, "date" => '2017-06-10', "payee" => "Starbucks"} ] }
before do
allow(ledger).to receive(:expenses_on)
.with('2017-06-10')
.and_return(expense_canned_response)
end
it "returns the expense records as JSON" do
get '/expenses/2017-06-10'
parsed = JSON.parse(last_response.body)
expect(parsed).to eq(expense_canned_response)
end
it "responds with a 200 (OK)" do
get '/expenses/2017-06-10'
expect(last_response.status).to eq(200)
end
end
context "when expenses don't exist on given date" do
let(:expense_not_found) { [] }
before do
allow(ledger).to receive(:expenses_on)
.with('2017-05-12')
.and_return(expense_not_found)
end
it "returns an empty array as JSON" do
get '/expenses/2017-05-12'
parsed = JSON.parse(last_response.body)
expect(parsed).to eq(expense_not_found)
end
it "responds with a 200 (OK)" do
get '/expenses/2017-05-12'
expect(last_response.status).to eq(200)
end
end
context "when the date format is not valid" do
it "returns a 400 Bad Request" do
get '/expenses/2012,12,12'
expect(last_response.status).to eq(400)
end
it "returns an error message" do
get '/expenses/2012,12,12'
expect(JSON.parse(last_response.body)).to eq({ "error" => "Invalid date format" })
end
end
end
end
end
I’ll add more routes and test cases so that I can practice more
- GET /expenses – List all expenses (not just by date)
- GET /expense/:id ————- These should added once we setup SQlite ————-
- DELETE /expenses/:id – Delete a specific expense
- PUT /expenses/:id – Update an existing expense
- GET /expenses/stats/:month – Show monthly summary
- POST /budgets – Set a budget limit for a category or month
- GET /categories
- GET /expenses?category=Food&date=2025-07-10 (this one needs
query params, we’re currently usingroute params)
In this chapter, we explored how to move from acceptance tests — which ensure that the entire application works as a whole — to unit tests, which isolate specific parts of the code, such as routing logic.
Unit tests typically run without a live server or real database, and instead focus on one class or method at a time. The benefits of this approach are faster test execution and clearer identification of where errors occur.
Rather than calling methods directly on the API class, we simulated HTTP requests using the Rack::Test interface. This aligns with the common testing principle of exercising a class through its public interface, which leads to better design decisions and a more user-focused API.
We also examined the Ledger class and introduced dependency injection (DI). In Ruby, this is as simple as passing an object as an argument to the constructor, like so:
initialize(ledger: Ledger.new)
This technique makes it easier to swap in test doubles when testing, allowing us to isolate the API class from the actual persistence layer.
A test double is a generic term for objects that stand in for real ones during testing. Depending on the testing framework, they might be called mocks, stubs, fakes, or spies. In RSpec, we use the term double. Our goal was to create a fake Ledger object to test only the API logic — without involving real data storage — making the tests faster and more focused. instance_double(class_to_fake)
We also encountered verifying doubles, a powerful RSpec feature that ensures your test doubles reflect the real object’s interface. This helps avoid fragile tests. In our case, forgetting to instantiate the Ledger correctly caused RSpec to raise an error — a valuable signal that our double wasn’t matching the actual interface.
If you ever need to inspect a full error stack trace during testing, you can run RSpec with the --backtrace or -b flag:
bundle exec rspec -b
Part II — Chapter 6. Getting real. Integration specs.
Now we have a solid HTTP routing layer designed with the help of unit specs. These specs assummed that the underlying dependencies would eventually be implemented.
Now, it’s time to write those dependecies for real.
Add the sequel and sqlite gems:
bundle add sequel sqlite3
Remember we need to have 3 differents databases for testing, development and production so that we dont clobber with real data.
Then add the 3 files (2 for configurations and 1 for the expenses migration)
# 04-acceptance-specs/01/expense_tracker/config/sequel.rb
require 'sequel'
DB = Sequel.sqlite("./db/#{ENV.fetch('RACK_ENV', 'development')}.db")
# 04-acceptance-specs/01/expense_tracker/spec/support/db.rb
# suite-level hook.
# The following code will make sure the database structure is set up and empty,
# ready for your specs to add data to it
RSpec.configure do |c|
c.before(:suite) do
Sequel.extension :migration
Sequel::Migrator.run(DB, 'db/migrations')
DB[:expenses].truncate
end
end
# 04-acceptance-specs/01/expense_tracker/db/migrations/0001_create_expenses.rb
Sequel.migration do
change do
create_table :expenses do
primary_key :id
String :payee
Float :amount
Date :date
end
end
end
Regarding the before(:suite) hook A typical hook will run before each example. This one will run just once: after all the specs have been loaded, but before the first one actually runs. That’s what before(:suite) hooks are for.
Then run the migration with bundle exec sequel -m ./db/migrations sqlite://db/development.db --echo
Outout you may see:
2025-08-05 13:32:31 INFO: (0.001937s) PRAGMA foreign_keys = 1
2025-08-05 13:32:31 INFO: (0.000010s) PRAGMA case_sensitive_like = 1
2025-08-05 13:32:31 INFO: (0.001011s) SELECT sqlite_version()
2025-08-05 13:32:31 INFO: (0.000890s) CREATE TABLE IF NOT EXISTS `schema_info` (`version` integer DEFAULT (0) NOT NULL)
2025-08-05 13:32:31 INFO: (0.000039s) SELECT * FROM `schema_info` LIMIT 0
2025-08-05 13:32:31 INFO: (0.000029s) SELECT 1 AS 'one' FROM `schema_info` LIMIT 1
2025-08-05 13:32:31 INFO: (0.000415s) INSERT INTO `schema_info` (`version`) VALUES (0)
2025-08-05 13:32:31 INFO: (0.000050s) SELECT count(*) AS 'count' FROM `schema_info` LIMIT 1
2025-08-05 13:32:31 INFO: (0.000028s) SELECT `version` FROM `schema_info` LIMIT 1
2025-08-05 13:32:31 INFO: Begin applying migration version 1, direction: up
2025-08-05 13:32:31 INFO: (0.000512s) CREATE TABLE `expenses` (`id` integer NOT NULL PRIMARY KEY AUTOINCREMENT, `payee` varchar(255), `amount` double precision, `date` date)
2025-08-05 13:32:31 INFO: (0.000423s) UPDATE `schema_info` SET `version` = 1
2025-08-05 13:32:31 INFO: Finished applying migration version 1, direction: up, took 0.001072 seconds
Then we had to create a spec/ledger_spec.rb which will test out the Ledger class behavior.
require_relative '../../../app/ledger'
require_relative '../../../config/sequel'
require_relative '../../support/db'
module ExpenseTracker
RSpec.describe Ledger, :aggregate_failures do
let(:ledger) { Ledger.new }
let(:expense) do
{
'payee' => 'Starbucks',
'amount' => 5.75,
'date' => '2017-06-10'
}
end
describe '#record' do
context "with a valid expense" do
it "succesfully saves the expense in the DB" do
result = ledger.record(expense)
expect(result).to be_success
expect(DB[:expenses].all).to match [a_hash_including(
id: result.expense_id,
payee: 'Starbucks',
amount: 5.75,
date: Date.iso8601('2017-06-10')
)]
end
end
end
end
end
And don’t forget to add the logic into the Ledger class
def record(expense)
DB[:expenses].insert(expense)
id = DB[:expenses].max(:id)
RecordResult.new(true, id, nil)
end
Here we just leveraged 2 new matchers be_success and match [a_hash_including] This particular example we detoured a bit from TDD since we declared 2 expects under the same it block but we did it judiciously since every test that touches the DB is slower so if we follow rigorously one expect per test case we’re going to be repeating that setup and teardown many times.
Also, we did added the metada :aggregate_failures so that RSpec doesn’t abort execution at the first error but to run all tests even with failures!
With this out of the way, let’s add a test for invalid records
it "rejects the expense as invalid" do
expense.delete('payee')
result = ledger.record(expense)
expect(result).not_to be_success
expect(result.expense_id).to eq(nil)
expect(result.error_message).to include('`payee` is required')
expect(DB[:expenses].count).to eq(0)
end
This will break our test, but that’s all the purpose of the red-green-refactor cycle. Now let’s add the valdiation for Ledger class
class Ledger
def record(expense)
unless expense['payee']
return RecordResult.new(false, nil, '`payee` is required')
end
DB[:expenses].insert(expense)
id = DB[:expenses].max(:id)
RecordResult.new(true, id, nil)
end
end
Something important that authors mention is that everytime we run the test suite we are adding records to our db which is not good practice, therefore they suggest to add the next RSpec configuration for leeting RSpec that everytime it finds :db tag, it should perform a DB transaction which will entails seting up the DB before running the tests and wiping out after the test suite is ran.
# suppor/db.rb
c.around(:example, :db) do |example|
DB.transaction(rollback: :always) { example.run }
end
Here is a detailed list of steps that this script will do:
- RSpec calls our
around hook, passing it the example we’re running. - Inside the hook, we tell Sequel to start a new database transaction.
- Sequel calls the inner block, in which we tell RSpec to run the example.
- The body of the example finishes running.
- Sequel rolls back the transaction, wiping out any changes we made to the database.
- The around hook finishes, and RSpec moves on to the next example.
Now let’s jump to implement the GET /expenses_on(:date) endpoint. First start with the test
describe "#expenses_on" do
it "returns all expenses for the date provided" do
result_1 = ledger.record(expense.merge('date' => '2017-06-10'))
result_2 = ledger.record(expense.merge('date' => '2017-06-10'))
result_3 = ledger.record(expense.merge('date' => '2017-06-11'))
expect(ledger.expenses_on('2017-06-10')).to contain_exactly(
a_hash_including(id: result_1.expense_id),
a_hash_including(id: result_2.expense_id)
)
end
it "returns an empty array when there are no matching expenses" do
expect(ledger.expenses_on('2017-06-10')). to eq([])
end
end
# then the ruby logic
def expenses_on(date)
DB[:expenses].where(date: date).all
end
This should pass all good!
Conclusion: while searching some other RSpec keywords i found this useful RSpec cheat sheet from Thoughtbot also we used the :aggregate_failures feature twice. This option allows the RSpec to continue running the entire test suite even when a test fails. We first applied it at the individual test case level, and then moved it up to an example group, which signaled RSpec to apply that behavior to the entire group.
We also introduced two new matchers: be_success and match a_hash_including.
Another key point we learned is that every spec interacting with the database will run more slowly. Because of this, we need to be judicious when applying the TDD methodology, which encourages writing one expect per test case. In some situations, we combined multiple expect statements within the same test case to speed up execution.
Finally, we explored the --bisect command, which is useful for identifying order-dependent tests. An order dependency occurs when a test fails only if another specific test runs before it. The --bisect command automatically isolates the minimal set of examples that cause the failure by repeatedly running subsets of your tests.
Example:
# First, run with a specific seed to reproduce the failure
rspec --seed 12345
# If you see a failure, run:
rspec --seed 12345 --bisect
Sample output:
Bisect started using options: "--seed 12345"
Reducing test suite by half...
...
The minimal reproduction command is:
rspec ./spec/foo_spec.rb[1:3] ./spec/bar_spec.rb[1:5] --seed 12345
This tells you exactly which tests together trigger the failure, so you can debug the cause. It’s essentially automated detective work for the classic “this test only fails when that other one runs first” problem.
Part III — RSpec Core.
Part III — Chapter 7. Structuring code examples.
we’ve gained the mental model of “where things go” (either files or groups or examples or setup!)
we’ve have written short, clear examples that explain exactly what the expected behavior of the code is laid examples into logical groups, not oly to share setup but foor keep related specs together
you’ll learn how to organize specs into groups, you’ll know where to put shared setup code and the trade-offs.
This will make the tests easier to read and maintain.
well-structures specs are about more than tidiness, sometimes you attach special behavior to certain examples or groups, like setting up a database or adding a custom error handling. the mechanism of metada (:tags) relies on good grouping.
Getting the words right.
Every RSpec is the example group in other testing Frameworks it is called test case class and it has multiple purposes:
- gives a logical structure for understanding how individual examples relate to one another
- describes the context such as a particular class, method or situation of what you are testing,
- provides a ruby class to act as a scope for your shared logic, such as hooks let definition and helper methods,
- runs, set up and tear down code shared by several examples.
The basic includes group examples, examples and expectations.
describe creates an example group. This is the place where you put what you say you are testing, the description can be either a string a ruby class, a module or an object. when you use a class it has some advantages because it requires the class to exist and to be spelled correctly, Also you place here the tag filtering with extra information and that tag will be applied to the nested examples
it creates a single example, you pass a description of the behavior you are specifying as with describe you can also pass custom metadata to make it more specific remember that for bdd the crucial part is to “getting the words right”.
Now, so much alternatives for describe that makes more sense when the examples within that group all relate to a single class method or module that alternative is context which will make it more readable and considering that this is for the long term maintainability, and it will show the intent behind the code.
another alternative is example instead of the it and it may be used when you are providing several data examples rather than several sentence about the subject or describing a behavior it will read much more clearly and lastly we have the specified instead of the it
RSpec also provides the flexibility for adding the names you want in the book shows how you can combine this gem with binding.pry and how you can add an alias to the spec_helper.rb file and use that in your Cascade or example and that will add the pry: trueto metadata to its respective example group or single example and with this you can quickly toggle the pry behavior on and off just by adding or removing the name you define in the spec_helper.rb.
Sharing logic.
the main three organization tools are let definitions, hooks, and helper methods below is a code snippet that contains all of the three
RSpec.describe 'POST a successful expense' do
# let definitions
let(:ledger) { instance_double('ExpenseTracker::Ledger') }
let(:expense) { { 'some' => 'data' } }
# hook
before do
allow(ledger).to receive(:record)
.with(expense)
.and_return(RecordResult.new(true, 417, nil))
end
# helper method
def parsed_last_response
JSON.parse(last_response.body)
end
end
We have used the let definition several times in this book they are great for setting up anything that can be initialized in a line or two of code, and they give you the lazy evaluation for free which means that they are not going to be run until you actually invoke them.
then we have the hooks that are for situations where they let definition block just won’t cut it. the important thing about hooks is the one and how often you want the hook to run.
Hooks.
“writing a hook involves two concepts. the type of hook controls when it runs relative to your examples. the scope controls how often your hook runs.”
For the when the hook should run we have three different types before, after, and around. as the name implies, you’re before hook will run before your examples. after hooks guarantee to run after your examples, even if the example fails or did before hook races an example. this hooks are intended to clean up after your setup logic and specs. this style of hook is easy to read, but it does split the setup and tear down logic into two halves that we have to keep track of.
When your database cleanup logic doesn’t fit neatly into a transactional around HOOK, we recommend using a before hook for the following reasons: if you forget to add the before hook to a particular spec the failure will happen in that example rather than a later one. when you run a single example to diagnose a failure the records will stick around in the database so that you can investigate them.
the around hook it’s a bit more complex because they sandwich your spec code inside your hook, so part of the hook runs before the example and part runs after. the behavior of these two Snippets is the same; it is just a question of which reads better for your application.
RSpec.describe MyApp::Configuration do
around(:example) do |ex|
original_env = ENV.to_hash
ex.run
ENV.replace(original_env)
end
end
Then we have the config hooks and this is if you need to run your hooks for multiple groups. you can define the hooks once for your entire Suite in the configuration typically spec _ helper.rband they’ll run for every example in your test suite
RSpec.configure do |config|
config.around(:example) do |ex|
original_env = ENV.to_hash
ex.run
ENV.replace(original_env)
end
end
and with this they will run for every example in your test suite note the trade-off here:
- Global hooks reduced duplication but can lead to surprising action at a distance effect in your aspects.
- hooks inside example groups are easier to follow but it is easy to leave out an important Hook by mistake when you are creating a new spec file.
we do recommend only use config hooks for things that are not essential for understanding how your specs work. the Beats of logic that isolate each example, such as a database transaction or environment sandboxing, or prime candidates.
we prefer to keep things simple and run our hooks unconditionally. if, however, our config hooks are only needed by a subset of examples on particularly if they are as low, we will use metadata to make sure they run only for the subset that need them.
now that we have seen when to run the hooks either before or after or around let’s see the scope.
this is meant when I hook needs to do a really timing tensive operation like creating a bunch of database tables or launching a live web server running the hook once per second will be cost provided. for this cases you can run the hook just once for the entire Suite of specs or once per example group. hooks take a symbol like :suite or :context argument to modify this code.
RSpec.describe 'Web interface to my thermostat' do
before(:context) do
WebBrowser.launch
end
after(:context) do
WebBrowser.shutdown
end
end
we only consider using context hook scope for side effects such as launching a web browser, that’s satisfy both of the following two conditions:
does not interact with things that have a per example life cycle is noticeable slow to run
when you use a context hook scope your responsible for cleaning up any resulting state otherwise, it can cause other specs to pass or fail incorrectly
this is particularly common problem with database code. any records created in a before context hook scope will not run in your per example database transactions. the records will stick around after the example groups
If you need to run a piece of setup call just once, before the first example begins that’s what :suite
There may be some old syntax that you may find in code bases which is Old new before(:each) became before(:example) before(:all) became before(:suite)
Something important when a example group is nested the before hooks run from the outside in and the after hooks run from the inside out.
when to use hooks we have seen that hooks serve two different purposes:
removing duplicate it or incidental details that will distract readers from the point of your example.
expressing the English descriptions of your example groups as executable code
Abusing RSpec hooks will make you skip all over your spec directory to trace program flow.
Helper methods.
Sometimes, we can get too clever for our own good and misuse these constructs in an effort to remove every last bit of repetition from our specs. Let’s see an example
RSpec.describe BerlinTransitTicket do
let(:ticket) { BerlinTransitTicket.new }
before do
# These values depend on `let` definitions
# defined in the nested contexts below!
#
ticket.starting_station = starting_station
ticket.ending_station = ending_station
end
let(:fare) { ticket.fare }
context 'when starting in zone A' do
let(:starting_station) { 'Bundestag' }
context 'and ending in zone B' do
let(:ending_station) { 'Leopoldplatz' }
it 'costs €2.70' do
expect(fare).to eq 2.7
end
end
context 'and ending in zone C' do
let(:ending_station) { 'Birkenwerder' }
it 'costs €3.30' do
expect(fare).to eq 3.3
end
end
end
With all these jumps around we have welcomed a behavior defined by the TDD community calls this separation of cause and effect a mystery guest link, now let’s see how would be with a smart usage of helper methods
RSpec.describe BerlinTransitTicket do
def fare_for(starting_station, ending_station)
ticket = BerlinTransitTicket.new
ticket.starting_station = starting_station
ticket.ending_station = ending_station
ticket.fare
end
context 'when starting in zone A and ending in zone B' do
it 'costs €2.70' do
expect(fare_for('Bundestag', 'Leopoldplatz')).to eq 2.7
end
end
context 'when starting in zone A and ending in zone C' do
it 'costs €3.30' do
expect(fare_for('Bundestag', 'Birkenwerder')).to eq 3.3
end
end
end
Now, it’s explicit exactly what behavior we’re testing, without our needing to repeat the details of the ticketing API. (these helper methods can be extracted into modules and be glued together by calling include into the group example)
Sharing examples groups
As we have seen, plain old Ruby modules work really nicely for sharing helper methods across example Scripts. but that’s all they can share. if you want to reuse an example, a let construct or a hook, you will need to reach for another two; shared example groups.
RSpec provides multiple ways to create and use shared sample grips. This come in pairs, with one method for defining a share group and another for using it:
- shared_context and include_context are for reusing common setup and helper logic..
- shared_example and include_exampleAre for reusing examples..
there is one more way to share behavior that is different, though. it_behaves_like creates a new, nested example to hold the shared code. the difference lies in how as isolated the shared behavior is from the rest of your examples.
Sharing context
Sooner or later, dough, you will find that you want to share some let declarations or hooks instead.
before do
basic_authorize 'test_user', 'test_password'
end
This hook cannot go into your modules. plane will be modules are not aware of our aspect constructs such as hooks. instead, you can convert your module to a shared context:
RSpec.shared_context 'API helpers' do
include Rack::Test::Methods
def app
ExpenseTracker::API.new
end
before do
basic_authorize 'test_user', 'test_password'
end
End
Here is how we use it:
RSpec.describe 'Expense Tracker API', :db do
include_context 'API helpers'
# .
Remember that sharing context is for reusing common setup and helper logic.
Sharing examples.
One of the most powerful ideas in software is defining a single interface with multiple implementation for example your web app might need to cash data in a key Value Store there are many implementation of this idea each which its own advantages over the others let’s see one example of these RS pack Behavior “shared_example”
require 'hash_kv_store'
RSpec.describe HashKVStore do
let(:kv_store) { HashKVStore.new }
it 'allows you to fetch previously stored values' do
kv_store.store(:language, 'Ruby')
kv_store.store(:os, 'linux')
expect(kv_store.fetch(:language)).to eq 'Ruby'
expect(kv_store.fetch(:os)).to eq 'linux'
end
it 'raises a KeyError when you fetch an unknown key' do
expect { kv_store.fetch(:foo) }.to raise_error(KeyError)
end
end
To test a second implementation of this interface such as a disk-backed FileKVStore – you could copy and paste the entire spec and replace all occurrences of HashKVStore store with FileKVStore. but then you will have to add any new common Behavior to both specs files. we will have to manually keep it two specs files in sync.
This is exactly the kind of duplication that shared example groups can help you fix. To make the switch, move your describe block into its own file and change it to a shared_example block taking an argument and use that argument in the let(:kv_store) declaration
RSpec.shared_examples 'KV store' do |kv_store_class|
➤ let(:kv_store) { kv_store_class.new }
it 'allows you to fetch previously stored values' do
kv_store.store(:language, 'Ruby')
kv_store.store(:os, 'linux')
expect(kv_store.fetch(:language)).to eq 'Ruby'
expect(kv_store.fetch(:os)).to eq 'linux'
end
it 'raises a KeyError when you fetch an unknown key' do
expect { kv_store.fetch(:foo) }.to raise_error(KeyError)
end
End
And we use it with the following code snippet:
require 'hash_kv_store'
require 'support/kv_store_shared_examples'
RSpec.describe HashKVStore do
it_behaves_like 'KV store', HashKVStore
end
Nesting
In the introduction to this section, we mentioned that you can include shared examples with either include_examples or it_behaves_like call. So far, we’ve just used It_behaves_like.
Calling include_examplesyou’d get two let declarations for :kv_store: one for HashKVStore and one for FileKVStore.
$ rspec spec/include_examples_twice_spec.rb --format documentation
Key-value stores
allows you to fetch previously stored values
raises a KeyError when you fetch an unknown key
allows you to fetch previously stored values
raises a KeyError when you fetch an unknown key
Finished in 0.00355 seconds (files took 0.10257 seconds to load)
4 examples, 0 failures
Using it_behaves_like avoids this issue:
RSpec.describe 'Key-value stores' do
it_behaves_like 'KV store', HashKVStore
it_behaves_like 'KV store', FileKVStore
End
This would output:
$ rspec spec/it_behaves_like_twice_spec.rb --format documentation
Key-value stores
behaves like KV store
allows you to fetch previously stored values
raises a KeyError when you fetch an unknown key
behaves like KV store
allows you to fetch previously stored values
raises a KeyError when you fetch an unknown key
Finished in 0.00337 seconds (files took 0.09726 seconds to load)
4 examples, 0 failures
When in doubt, choose it behaves like
it behaves like it’s almost always the one you want. it ensures that the contents of the Share Group don’t leak into the surrounding context and interact with your other examples.
we recommend using include examples only when you are sure that shared example context on conflict with anything in the surrounding group.
This is a table that wraps up all the key Concepts that we saw:
| Concept | Usage | Gotcha |
|---|---|---|
| describe | Creates an example group for a class, module, object, or string; can combine with string; supports metadata. | Passing a class enforces existence and correct spelling; vague descriptions reduce clarity. |
| context | Alias for describe when grouping by situation or condition. |
Misuse can make specs awkward (“describe when boiling”). |
| it | Defines a single example with behavior description; supports metadata. | Reads awkwardly if not describing a subject. |
| example | Alias for it; better for listing data cases. |
None — just improves readability. |
| specify | Alias for it; use when neither it nor example reads well. |
None — clarity preference only. |
| hooks | Shared setup/teardown logic with before, after, or around. |
Overuse can cause “mystery guest” indirection; keep near usage. |
| before(:example) | Runs before each example (default scope). | Forgetting in a spec causes failure there; can hide setup details. |
| after(:example) | Runs after each example, even on failure. | Setup/teardown split can be harder to follow; prefer before for DB cleanup. |
| around(:example) | Wraps code before and after an example in one block. | Only supports :example scope; can be harder to read. |
| config hooks | Hooks in RSpec.configure for the whole suite. |
Risk of “action at a distance”; use for incidental details. |
| scopes | :example (default), :context (once/group), :suite (once/suite). |
:context can leak state; :suite only in config; avoid old :each/:all. |
| global hooks | Config hooks affecting all examples. | Can cause unintended side effects; harder to trace. |
| hooks inside example groups | Hooks scoped to one group. | Easier to follow, but may be missed in new files. |
| before(:context) | Runs once before all examples in a group. | Avoid for DB records or per-example lifecycle items; must clean up state. |
| after(:example) | Runs after each example; used for cleanup, even if the example fails. | Splits setup and teardown logic across hooks, making flow harder to follow; prefer before for database cleanup. |
| let definition | Lazily defines a memoized helper variable. | Overuse can hide cause/effect; nested overrides may confuse. |
| helper method | Ruby method in example group for setup or reuse. | Avoid hiding essential details far away; inline when important. |
| shared_context + include_context | Share let, hooks, and helpers across groups. |
Plain Ruby modules can’t hold RSpec constructs; merging may override definitions. |
| shared_examples + include_examples | Share examples; include_examples pastes into current group. |
Multiple includes can cause collisions (e.g., let overwrites). |
| it_behaves_like | Runs shared examples in a nested group, avoiding collisions. | Adds extra nesting in output; almost always preferred to include_examples. |
Part III — Chapter 8. Slicing and dicing specs with metadata.
Slicing and Dicing specs with Metadata
In this chapter we are going to learn what type of information are spec stores for each example that it is run how to add more information to that previous stack coma and how to read it, how to perform expensive setup only when we need it and how to run just a subset of tests.
over the course of this book, we have far away cute principle that has made our specs faster, more reliable, and easier to use: “ run just the code you need.” when you are isolating a failure, run just the feeling example. when you are modifying a class, run just it’s unit tests. when you’ve got expensive setup code, only run it for the specs where you need it.
a key piece of RS pack that’s made many of these practices possible is its powerful metadata system. metadata undergirds many of our aspects features, and rs back exposes the same system for your use.
Defining metadata
where do I keep information about the context my specs are running in? by contact, we mean things like: example configuration open parentheses for example, Mark as escaped or pending close parentheses source code locations status of the previous run how one example runs differently than others for example needing a web browser or a DB
without some way of attaching data to examples, you and the are aspect maintainers will be stock juggling Global variables and writing a bunch of bookkeeping code..
RSpec solution to this problem couldn’t beSimpler: a plain Ruby hash. every example an example group gets its own such hash, known as the metadata hash.RSpec populates this hash with any metadata you have explicitly chat the example with, plus some useful entries of its own.
If you create the following file and you run the test you will see the next information on your terminal:
require 'pp'
RSpec.describe Hash do
it 'is used by RSpec for metadata' do |example|
pp example.metadata
end
end
# this w ould be the output
$ rspec spec/metadata_spec.rb
{:block=>
#<Proc:0x007fa6fc07e6a8@~/code/metadata/spec/metadata_spec.rb:4>,
:description_args=>["is used by RSpec for metadata"],
:description=>"is used by RSpec for metadata",
:full_description=>"Hash is used by RSpec for metadata",
:described_class=>Hash,
:file_path=>"./spec/metadata_spec.rb",
:line_number=>4,
:location=>"./spec/metadata_spec.rb:4",
:absolute_file_path=>
"~/code/metadata/spec/metadata_spec.rb",
:rerun_file_path=>"./spec/metadata_spec.rb",
:scoped_id=>"1:1",
:execution_result=>
#<RSpec::Core::Example::ExecutionResult:0x007ffda2846a78
@started_at=2017-06-13 13:34:00 -0700>,
:example_group=>
{:block=>
#<Proc:0x007fa6fb914bb0@~/code/metadata/spec/metadata_spec.rb:3>,
« truncated »
:shared_group_inclusion_backtrace=>[],
:last_run_status=>"unknown"}
.
Finished in 0.00279 seconds (files took 0.09431 seconds to load)
1 example, 0 failures
Listen if it shows something that we haven’t talked about before: getting access to your examples properties at the wrong time. you can so by having your eight block take an argument. it will pass an object representing the currently running example.
the call to example that metadata returns a hash containing all the metadata. kiss like description just the string we passed to it, full description includes the checks passed to the describe, describe class, fire path, example groups and last round status with four different values as past, pending, failed or unknown
Custom metadata
if we want to add extra metadata to our examples in order to identify it better or to one our colleagues we can do it with the next procedure:
require 'pp'
RSpec.describe Hash do
➤ it 'is used by RSpec for metadata', :fast do |example|
pp example.metadata
end
end
# this will save`:fast=>true`, we can also add more than one, for example :fast, :focus
Then we can call those example that contain the :fast meta tag with $ rspec --tag fast
We can also do it for all examples by adding it to spec_helper.rb
RSpec.configure do |config|
config.define_derived_metadata(file_path: /spec\/unit/) do |meta|
meta[:fast] = true
end
end
Default metadata
As we saw previously with the tag :aggreagate_failuresWhich will run all the test even when they fail, we can add these two all of the examples again adding it to the RSpec.configure
RSpec.configure do |config|
config.define_derived_metadata do |meta|
# Sets the flag unconditionally;
# doesn't allow examples to opt out
meta[:aggregate_failures] = true
end
end
Here is something important that if we don’t want to use that metal type the next code will be overwritten by the global setting:
RSpec.describe 'Billing', aggregate_failures: false do
context 'using the fake payment service' do
before do
expect(MyApp.config.payment_gateway).to include('sandbox')
end
# ...
end
end
Therefore we need to tweak it a little bit in order to allow the example group to follow its own rules we need to add a conditional to the spec helper
RSpec.configure do |config|
config.define_derived_metadata do |meta|
meta[:aggregate_failures] = true unless meta.key?(:aggregate_failures)
end
end
I say recap of this chapter we can conclude that it will be hash is created every time we run our test Suite and wouldn’t that hash we can find configurations, where the code is located, status of the example, we can even add our own tags And we can print that hash at the wrong time with .metadata
Selecting which specs to run
When you are running your specs, you often want to change which ones you include. in this section we are going to show you a few different situations where this kind of slicing and dicing comes in handy.
most of the time when we start writing our tests, we don’t run then Tire so. we are either running unit spec for a specific class we are designing or we are kicking off some integration specs to catch regressions.
one example to exclude some examples is the following tag:
RSpec.configure do |config|
config.filter_run_excluding :jruby_only unless RUBY_PLATFORM == 'java'
end
The filter_run_excluding call indicates which examples we’re leaving out. The flip side to that method is filter_run_including, or just filter_run for short.
This style of filtering is pretty brute-force. If no examples match the filter, RSpec will run nothing at all. A more generally useful approach is to use filter_run_when_matching. With this method, if nothing matches the filter, RSpec just ignores it.
Remember that RSpec.configure block are permanent settings, baked into your setup code. They’ll be in effect every time you run RSpec.
If you want to run your specific subset of tests from command line you can do it with the following
$ rspec --tag fast # this will run just the examples tagged with :fast
# this will do exactly the opposite, run all except the tests tagged with :fast
$ rspec --tag ~fast
Sharing code conditionally
we discussed three ways to share code across many examples groups: top level config hooks modules containing helper methods shared context containingRSpec constructs such as Hooks and let blocks
Metadata is what enables this flexibility, and you can use it with all the culture and techniques we listed earlier:
Config hooks. pass a filter expression as a second argument to config.before, config.after or config.aroundTo run that hook only for example matching the filter.
# spec/spec_helper.rb
RSpec.configure do |config|
config.before(:example, :db) do
puts "Setting up database for this example..."
end
config.after(:example, slow: true) do
puts "Cleaning up after a slow example..."
end
config.around(:example, api: true) do |example|
puts "Before API example"
example.run
puts "After API example"
end
end
# Usage in a spec:
RSpec.describe "Some feature" do
it "needs database setup", :db do
# ...
end
it "is a slow example", slow: true do
# ...
end
it "calls the API", api: true do
# ...
end
end
modules. at the filter expression to the end of your config that include call in order to include a module and it’s helper methods conditionally. this also works for similar config.extend and config.prepend
# spec/support/api_helpers.rb
module APIHelpers
def api_call(path)
# pretend API call here
end
end
# spec/spec_helper.rb
RSpec.configure do |config|
config.include APIHelpers, api: true
end
# Usage:
RSpec.describe "API requests", :api do
it "can call the API" do
api_call("/status")
end
end
shared context. just ask with modules, at a filter expression when calling config.include_contest. this will bring in your shirt let constructs among other things into just example groups you want.
# spec/support/api_context.rb
RSpec.shared_context "API context" do
let(:auth_token) { "secret" }
end
# spec/spec_helper.rb
RSpec.configure do |config|
config.include_context "API context", api: true
end
# Usage:
RSpec.describe "Authenticated API request", :api do
it "uses the auth token" do
expect(auth_token).to eq "secret"
end
end
Here are some other examples of metadata that we have seen before
| Tag | Usage | Gotcha |
|---|---|---|
| :aggregate_failures | Allows multiple expectations in an example to run before failing, showing all failures together. | Without it, the first failing expectation stops the example; can hide which expectation failed first. |
| :pending | Marks an example as pending (not yet implemented or expected to fail). | If the example passes, RSpec flags it as a failure to remind you to remove :pending. |
| :order | Sets run order for examples (e.g., :random, :defined). |
Random order may expose order dependencies; :defined can hide them. |
| :skip | Skips the example or group entirely without running it. | Easy to forget skipped tests; may hide failing scenarios if left in place. |
Part III — Chapter 9. Configuring RSpec.
As you have work through there exercises in this book, you have often change RS specs Behavior to make it a better tool for your needs here are just a few of the things that you have customized:
set up until you’re down a test database, but only for the examples that require one report every failing expectation in an example not just the first one run just examples that you are focusing on at the moment
you can configure rspec into basic ways: on rspec.configure block: provides access to all configuration options: since the block lives in your code, you will typically use it to make permanent changes command line options: provides access to some configurations options, typically one off settings
Command line configurations
to see all available command line options, run rspec –help and you’ll see in you terminal options for:
- calling, loading files or directories
- tweak the output (formatting, write output in a file, backtrace, color, no color)
- filtering/tags, (match a word, only run a specific example, all failures, next failure)
- Utility (Initialize your project with RSpec, run RSpec version)
R s p e c already asked the two most important directories to load path your projects leave and expect folders.
we have filtering options like the following
we have output options like the following
and if you want to save this options to customize the behavior for everyone we have three different options
| File | Usage | Gotcha |
|---|---|---|
| ~/.rspec | Stores global personal RSpec preferences for all projects on your machine. | Affects every project; avoid settings that could break others’ test runs if shared. |
| ./.rspec | Project-level defaults; should contain only essential settings agreed upon by the team. | Overusing for personal prefs can cause conflicts; always commit only team-approved settings. |
| ./.rspec-local | Per-project personal preferences; lives alongside the project’s .rspec file. |
Exclude from version control; every developer may have their own version. |
something to keep in mind is that the order that we have listed above is how options take precedence, local options will override more global ones. For instance, if your project has --profile 5 set in its .rspec file, you could override this setting by putting --no-profile in the project’s .rspec-local file.
Using a custom formatter
a question for matter is a regular Ruby class that registers itself with rspec to receive notification. as your suite runs, rspec notifies the formatter of the events it is subscribed to, such as starting an example group, running an example, or encountering a failure.
R s p e c s built in formatters display failure details, messages and back traces, at the very end of the run. however, as you suite grows and start thinking longer to complete, it can be nice to see failure details as soon as they are cure. How far matters work.
a formatter goes through three main steps: register itself with rspec to receive a specific notifications initialize itself at the beginning of the rsvc Run react to events as they occur
RSpec.configure
We have seen how easily we can set configuration options for a particular spec run via the command line. as convenient as they are this modifications are not available for all the test suit. for the rest will need to call RS p e c. configure inside one or more Ruby files. you can have multiple configure blocks in your code base; if you do rspec will combine the options from all of them.
Cuz we have seen before a hook can run for each example, once for each context, or globally for the entire suit .
We also have other special purpose configuration hook that doesn’t fit the typical before, after, around pattern. and example would be
RSpec.configure do |config|
config.when_first_matching_example_defined(:db) do
require 'support/db'
end
end
This hook uses metadata :db to perform extra configuration just for the specs that needed.
while config hooks are great way to reduce duplication and keep your example focused, there are significant downsides if you overuse them: it’s low test suit due to extra logic running for every example spec star hotter to understand because their logic is hidden in hooks to avoid this pitfalls you can use a simpler, more explicit technique: using Ruby modules inside your configure blocks.
Sharing code with Ruby modules
# spec_configure.rb
class Performer
include Singing # won't override Performer methods
prepend Dancing # may override Performer methods
end
You can even bring methods into an individual object:
# spec_configure.rb
average_person = AveragePerson.new
average_person.extend Singing
RSpec provides the same kind of interface inside RSpec.configure blocks. By calling include, prepend, or extend on the config object
RSpec.configure do |config|
# Brings methods into each example
config.include ExtraExampleMethods
# Brings methods into each example,
# overriding methods with the same name
# (rarely used)
config.prepend ImportantExampleMethods
# Brings methods into each group (alongside let/describe/etc.)
# Useful for adding to RSpec's domain-specific language
config.extend ExtraGroupMethods
end
These three config methods are great for sharing Ruby methods across the respects. if you need to share more, though such as hooks or let definitions, you will need to define a shirt example group.
# spec_configure.rb
RSpec.configure do |config|
config.include_context 'My Shared Group'
end
Filtering
we have found the need to run just some of the examples in your suit therefore we have used rsps filtering to run the following subsets of specs: a single example or group by name only the specs matching a certain piece of metadata such as :fast
Some of the rspec configuration system that we have used inside of our configure block are the following
RSpec.configure do |config|
config.filter_run_when_matching :focus # Runs only examples/groups tagged with :focus
config.example_status_persistence_file_path = 'spec/examples.txt' # Stores example run status for --only-failures/--next-failure
config.filter_gems_from_backtrace 'rack', 'rack-test', 'sequel', 'sinatra' # Removes listed gems from failure backtraces
config.filter_run_when_matching :focus # Duplicate line; same as first setting above
end
And if I was reviewing the directory of the exercises from Facebook are realized that the configure block is almost everywhere either from the root directory to a specific model specs files where we need it a more granually effect on the test running
As a conclusion for this chapter we have explored that we have two ways to configure the rspec testing framework one is from the command line and the other is with the configure method. command line options are easy to discover and they are one off to modify the next output the next format or to run a subset of tests on the other hand with configure method covers the whole test suit and also we can have more control as we declare those configure blocks inside of the files
Part IV — RSpec expectations.
With rspec-expectations, you can easily express expected outcomes about your code. It uses simple matcher objects that can be composed in useful, powerful ways.
We’ll dig into how rspec-expectations works, how to compose matchers, and why doing so is useful.
Part IV — Chapter 10. Exploring RSpec expectations.
In RSpec Core, we saw how rspec-core helps you structure your test code into example groups and examples. but having a sound structure is not enough for writing good tests. If our specs run code without looking at the output, we are not really testing anything, except the code doesn’t crash outright. That’s where RSpec-expectations comes in. it provides an API for a specifying expected outcomes.
RSpec example should contain one or more expectations. This express what you expect to be true at a specific point in your code.
In this chapter, we’ll see how one crucial part of expectations – the matcher can be combined in useful new ways.
ratio = 22 / 7.0
expect(ratio).to be_within(0.1).of(Math::PI)
numbers = [13, 3, 99]
expect(numbers).to all be_odd
alphabet = ('a'..'z').to_a
expect(alphabet).to start_with('a').and end_with('z')
The primary goal of rspec-expectations is clarity, both in the examples you write and in the output when something goes wrong.
Parts of an expectation:
expect(deck.cards.count).to eq(52), 'not playing with a full deck'
While there is some variety here, the syntax consistently uses just a few example parts:
- A subject - the thing you are testing, that is, an instance of a Ruby class.
- A matcher - an object that specifies what you expect to be true about the subject, and provides the past or fail logic
- (Optionally) a custom failure message

irb session
irb(main):001> require 'rspec/expectations'
=> true
irb(main):002> include RSpec::Matchers
=> Object
irb(main):003> expect(1).to eq(1)
=> true
irb(main):004> expect(1).to eq(2)
/Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rspec-support-3.13.4/lib/rspec/support.rb:110:in 'block in <module:Support>': (RSpec::Expectations::ExpectationNotMetError)
expected: 2
got: 1
(compared using ==)
Wrapping your subject with expect
Ruby begins evaluating your expectation at the expect method.
Let’s go to irb session again:
irb(main):005> expect_one = expect(1)
=>
#<RSpec::Expectations::ValueExpectationTarget:0x000000013ad9...
irb(main):006> expect_one
=>
#<RSpec::Expectations::ValueExpectationTarget:0x000000013ad99708
@target=1>
Here, our subject is the number 1. We have wrapped in the expect method to give ourself a place to attach methods like to or not_to. in other words the expect methods wraps are object in a test friendly adapter.
Side note: prior versions of RSpec expect method what should and should_not respectively.
Using a matcher
If expect wraps your object for testing, then the matcher actually performs the test. The matcher checks that the subject satisfies its criteria. matcher can compare numbers, find patterns in text, examine deeply nested data structures or perform any custom Behavior you need.
The RSpec::Matchers module ships with built-in methods to create matchers:
irb(main):007> be_one = eq(1)
=>
#<RSpec::Matchers::BuiltIn::Eq:0x000000013abf9808
...
irb(main):008> be_one
=>
#<RSpec::Matchers::BuiltIn::Eq:0x000000013abf9808
@expected=1>
This matcher can’t do anything on its own; we still need to combine it with the subject we saw in the previous section.
Please, notice how expect(1) built an ExpectationTarget object internally returns:
@target → is the actual value you passed in (1 in our example).
This object is just a holder for that value, plus some helper methods like .to and .not_to
Then, with eq(1) built a matcher object (in this case RSpec::Matchers::BuiltIn::Eq).
And internally @expected → is the value you want to match against (1 here).
irb(main):011> expect_one.to(be_one)
=> true
irb(main):012> expect_one.not_to(be_one)
/Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rspec-support-3.13.4/lib/rspec/support.rb:110:in 'block in <module:Support>': (RSpec::Expectations::ExpectationNotMetError)
expected: value != 1
got: 1
(compared using ==)
The to method tries to match the subject (in this case, the integer 1) against the provided matcher. If there’s a match, the method returns true; if not, it bails with a detailed failure message.
The not_to method does the opposite:
irb(main):017> expect_one.not_to eq(be_one)
=> true
irb(main):014> expect(1).not_to eq(2)
=> true
When you think of RSpec expectations as being just a couple of simple Ruby objects glued together, the syntax becomes clear. You’ll use parentheses with the expect method call, a dot to attach the to or not_to method, and a space leading up to the matcher (maybe eq).
Custom failure messages.
Let’s see an example of a very brief Ruby code that will show us a technically correct error however we can make it more explicit by adding an alternate failure message along to the matcher to or not_to
irb(main):018> resp = Struct.new(:status, :body).new(400, 'unknown query param `sort`')
=> #<struct status=400, body="unknown query param `sort`">
irb(main):019> expect(resp.status).to eq(200)
/Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rspec-support-3.13.4/lib/rspec/support.rb:110:in 'block in <module:Support>': (RSpec::Expectations::ExpectationNotMetError)
expected: 200
got: 400
(compared using ==)
irb(main):020> expect(resp.status).to eq(200), "Got a #{resp.status}: #{resp.body}"
/Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rspec-support-3.13.4/lib/rspec/support.rb:110:in 'block in <module:Support>': Got a 400: unknown query param `sort` (RSpec::Expectations::ExpectationNotMetError)
When the matchers default failure message doesn’t provide enough detail, a custom message maybe just what you need. You can save time by writing your own matches instead if you find yourself using the same message repeatedly.
Assertions are simpler to explain than RSpec’s expectations—and simplicity is a good thing—but that doesn’t necessarily make one better than the other.
| Concept | Why | Code example |
|---|---|---|
| Composability | Matchers are first-class objects that can be combined and used flexibly. | expect(score).to be > 5 & be < 10 |
| Negation | Any matcher can be negated with not_to without writing a separate refute method. |
expect(user.active?).not_to be true |
| Readability | Syntax reads like an English sentence describing the expected outcome. | expect(order.total).to eq 100 |
| More useful errors | Failure messages clearly show which part failed, unlike generic assertions. | expect([13, 2, 3, 99]).to all be_odd |
How matchers work
Any Ruby object can be used as a matcher as long as it implements a minimal set of methods (.matches? and .failure_message), let’s build one in irb
irb(main):021> matcher = Object.new
=> #<Object:0x0000000138954280>
irb(main):022> expect(1).to matcher
/Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rspec-expectations-3.13.5/lib/rspec/matchers.rb:968:in 'RSpec::Matchers#method_missing': undefined method 'matches?' for #<Object:0x0000000138954280> (NoMethodError)
Did you mean? match
This expectation has triggered a NoMethodError exception. RSpec expects every matcher to implement a matches? method, which takes an object and returns true if the object matches (and false otherwise).
irb(main):027* def matcher.matches?(actual)
irb(main):028* actual == 1
irb(main):029> end
=> :matches?
irb(main):030> expect(1).to matcher
=> true
When the match fails, RSpec expectations calls the matcher’s failure_message method
irb(main):031> expect(2).to matcher
/Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rspec-expectations-3.13.5/lib/rspec/matchers.rb:968:in 'RSpec::Matchers#method_missing': undefined method 'failure_message' for #<Object:0x0000000138954280> (NoMethodError)
# here we implemented the .failure_message
irb(main):035* def matcher.failure_message
irb(main):036* 'expected object to equal 1'
irb(main):037> end
=> :failure_message
irb(main):038> expect(2).to matcher
/Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rspec-support-3.13.4/lib/rspec/support.rb:110:in 'block in <module:Support>': expected object to equal 1 (RSpec::Expectations::ExpectationNotMetError)
These two methods matches? and failure_message are all you need to define a simple matcher.
Where the matchers really shine is when you compose them with other matchers to specify exactly what you expect and nothing more. the result is more robust tests and fewer false failures. Here are a few different ways to compose matchers:
| Technique | Usage | Code example |
|---|---|---|
| Pass matcher into another | Use a matcher as an argument to another matcher. | expect(result).to start_with a_string_matching(/Hello/) |
| Embed in Array/Hash | Place matchers inside arrays or hashes to match structure and values. | expect(user).to match(name: a_string_starting_with("A")) |
| Logical operators | Combine matchers with & (and) or | (or). |
expect(score).to be > 5 & be < 10 |
How matchers match objects
Matchers build on top of Ruby’s standard protocols in order to provide composability: the humble === method. This method, often called “three equals” or “case equality” defines a category to which other objects may or may not be long. most of the time you wont call it directly from production code. Instead, Ruby will call it for you inside each one class of a case expression
irb(main):039* def describe_value(value)
irb(main):040* case value
irb(main):041* when be_within(0.1).of(Math::PI) then 'Pi'
irb(main):042* when be_within(0.1).of(2 * Math::PI) then 'Double Pi'
irb(main):043* end
irb(main):044> end
=> :describe_value
irb(main):045> describe_value(3.14159)
=> "Pi"
irb(main):046> describe_value(6.28319)
=> "Double Pi"
RSpec expectations perform the same check internally that Ruby’s case statement does: they call === on the object you pass in. that object can be anything, including another matcher.
Passing one matcher into another
It may not be obvious why you would need to pass a matcher to another matcher. that say you expect a particular array to start with a value that’s near pi. with rspec, you can pass the be_within(0.1).of(Math::PI) matcher matcher into the start_with
irb(main):047> numbers = [3.14159, 1.734, 4.273]
=> [3.14159, 1.734, 4.273]
irb(main):048> expect(numbers).to start_with( be_within(0.1).of(Math::PI) )
=> true
irb(main):049> expect([]).to start_with( a_value_within(0.1).of(Math::PI) )
/Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rspec-support-3.13.4/lib/rspec/support.rb:110:in 'block in <module:Support>': expected [] to start with a value within 0.1 of 3.141592653589793
Embedding matches in Array and hash data structures
This ability to compose matchers—by passing them into one another, or by embedding them in data structures—lets you be as precise or as vague as you need to be.
In other matchers like match_array or contain_exactly, RSpec does recursively apply matchers inside arrays and hashes, but start_with (and end_with) do not.
irb(main):069* presidents = [
irb(main):070* { name: 'George Washington', birth_year: 1732 },
irb(main):071* { name: 'John Adams', birth_year: 1735 },
irb(main):072* { name: 'Thomas Jefferson', birth_year: 1743 },
irb(main):073* # ...
irb(main):074> ]
=>
[{name: "George Washington", birth_year: 1732},
...
irb(main):075* expect(presidents).to start_with(
irb(main):076* match(name: 'George Washington', birth_year: a_value_between(1730, 1740)),
irb(main):077* match(name: 'John Adams', birth_year: a_value_between(1730, 1740))
irb(main):078> )
=> true
Combining matters with logical and or operators
There’s another way to combine matchers: compound matcher expressions. Every built-in matcher has two methods (and and or).
irb(main):079> alphabet = ('a'..'z').to_a
irb(main):080>
=>
["a",
...
irb(main):081> expect(alphabet).to start_with('a').and end_with('z')
irb(main):082>
=> true
irb(main):083> stoplight_color = %w[ green red yellow ].sample
irb(main):084>
=> "yellow"
irb(main):085> expect(stoplight_color).to eq('green').or eq('red').or eq('yellow')
irb(main):086>
=> true
You can use the words and/or, or you can use the & and | operators
Generated example descriptions
Matchers have another useful ability over simpler assert methods: they’re selfdescribing.
irb(main):087> start_with(1).description
=> "start with 1"
irb(main):088> (start_with(1) & end_with(9)).description
=> "start with 1 and end with 9"
irb(main):089> contain_exactly( a_string_starting_with(1) & ending_with(9) ).description
=> "contain exactly (a string starting with 1 and ending with 9)"
As you can see, the descriptions of composed and compound matchers include the description of each part.
Part IV — Chapter 11. Matchers included in RSpec expectations.
In the previous chapter, we learned how to write expectations to check your codes behavior. We got to know the various parts of an expectation like a subject and the matcher.
Now, it’s time to take a closer look at matchers. You have called them in your specs and combine them with other matchers. RSpec ships with a ton of useful matchers to help you specify exactly how you want the code to behave.
The matchers in RSpec expectations fall into three growth categories:
- Primitive: matchers for basic data types like strings, numbers and so on
- High order matchers: that can take other matchers as inputs, then apply them across collections
- Block matchers: for checking properties of code including blocks, exceptions, and side effects.
Primitive matches
The word primitive in a programming language refers to a breath and butter data type that cannot be broken down into a smaller pieces. booleans, integers, and floating point numbers are all primitives.
Primitive matchers are similar. They have simple, precise definitions that cannot be broken down any further. They are not meant to accept other matchers as input (but you can go the other direction, passing them into other matchers). Typically, they just pass the operation you are performing - and equality check, for example a straight through the subject of the expectation.
Equality and identity
Most fundamentals matchers are all concerned with variations of the question: “are these two things the same?”, depending on the context. “The same” might refer to one of the several things:
-
Identity: for example, two references to one object
-
Hash key equality: two objects of the same type and value, such as two copies of the string “hello”.
-
Value equality: two objects of compatible types with the same meaning, such as the integer 42 on the floating Point number 42.0
Value equality
Most of the time, Ruby programmers are concerned with the last of these: value equality, embodied in Ruby’s === operator.
This matcher is the one you want. However, sometimes you have a more specific me.
expect(Math.sqrt(9)).to eq(3)
# equivalent to:
Math.sqrt(9) == 3
Identity
perms = Permutations.new
first_try = perms.of(long_word_list)
second_try = perms.of(long_word_list)
expect(second_try).to eq(first_try)
This test will likely give you a false assurances. If the underlying cache is misbehaving or was never implemented, the calculation will just run again and produce a new word list in the same order. Because both arrays have the same contents, your test will incorrectly pass.
Instead, you would like to know whether or not first_try and second_try are actually referring to the same underlaying object, not just two copies with identical contents.
For this stricter comparison, you will use equal matcher, which hands off to Ruby’s equal? method behind the scenes:
expect(second_try).to equal(first_try)
If you prefer you can also use be(x) as an alias for equal(x) to emphasize that this matcher is about identity rather than value equality
expect(RSpec.configuration).to be(RSpec.configuration)
Hash key equality
Programmers rarely check hash key equality directly. As the name implies, it’s used to check that two values should be considered the same Hash key.
RSpec eql matcher, based on Ruby’s built-in eql? method, checks for hash key equality. Generally, it behaves the same as the eq matcher since eql? always considers integers and floating point numbers to be different.
# 3 == 3.0:
expect(3).to eq(3.0)
# ...but 3.eql?(3.0) is false:
expect(3).not_to eql(3.0)
This behavior allows 3 and 3.0 to be used as different keys in the same hash.
Variations
All three of these matchers have aliases that read better in composed matcher expressions:
an_object_eq_toaliaseseq(identity)an_object_equal_toaliasesequal(value equality)an_object_eql_toaliaseseql(hash key equality)
For instance, consider the following expectation that checks a list of Ruby classes:
expect([String, Regexp]).to include(String)
The intent was to require the actual Ruby String class to be present. Higher-order matchers like include check
their arguments with the three-quals operator, ===. In this case, RSpec ends up checking String === ‘a string’, which returns true.
The fix is to pass the an_object_eq_to
expect([String, Regexp]).to include(an_object_eq_to String)
Truthiness
While Ruby has literal true and false values, it allows any object to be used in a conditional. The rules are very simple false and nil are both treated as false, and everything else is treated as true even the numbers 0.
expect(true).to be_truthy
expect(0).to be_truthy
expect(false).not_to be_truthy
expect(nil).not_to be_truthy
# ...and on the flip side:
expect(false).to be_falsey
expect(nil).to be_falsey
expect(true).not_to be_falsey
expect(0).not_to be_falsey
If you want to specify that the value is precisely equal to true or false, simply use one of the equality matchers we described in the last section:
expect(1.odd?).to be true
expect(2.odd?).to eq false
Alises:
• be_truthy is aliased as a_truthy_value.
• be_falsey is aliased as be_falsy, a_falsey_value and a_falsy_value.
Operator comparisons
We have used thebe method with arguments before, as in expect(answer).to be(42). This method has another form, one without arguments. with it you can perform greater-than and less-than comparisons:
expect(1).to be == 1
expect(1).to be < 2
expect(1).to be <= 2
expect(2).to be > 1
expect(2).to be >= 1
expect(String).to be === 'a string'
expect(/foo/).to be =~ 'food'
In each case, RSpec uses your operator such as == or < to compare the actual and the matcher on the first line, be == 1, is equivalent to eq(1).
Delta and range comparisons
Checking two floats for exact equality will frequently cause failures
expect(0.1 + 0.2).to eq(0.3)
…then you get a failure:
expected: 0.3
got: 0.30000000000000004
(compared using ==)
Absolute difference
Instead of looking for exact equality with floats, you should use be_within matcher:
expect(0.1 + 0.2).to be_within(0.0001).of(0.3)
Relative difference
Equally useful is the percent_of method, where you give a relative difference instead:
town_population = 1237
expect(town_population).to be_within(25).percent_of(1000)
A single be_within matcher supports both absolute and relative values, based on which method you chain off of it
Ranges
Sometimes, it’s a better fit to express your expected values in terms of a range, rather than a target value and delta.
expect(town_population).to be_between(750, 1250)
` be_within is aliased to a_value_within and be_between is aliased to a_value_between`
Dynamic predicates
A predicate is a method that answers a question with a Boolean answer. For example, Ruby’s Array class provides an empty? method rather than is_empty.
expect([]).to be_empty
You can alternately use a be_a_ or be_an_ prefix for predicates that are nouns.
expect(user).to be_admin
expect(user).to be_an_admin
hash = { name: 'Harry Potter', age: 17, house: 'Gryffindor' }
expect(hash).to have_key(:age)
How Dynamic Predicate Matchers Work
- You write:
expect(user).to be_admin - RSpec sees: “Hmm, I don’t recognize
be_admin, but it follows the patternbe_*” - RSpec transforms it: Strips off
be_, adds?, and calls that method on the subject - RSpec actually calls:
user.admin?
# What you write → What RSpec calls
expect(user).to be_admin → user.admin?
expect([]).to be_empty → [].empty?
expect(str).to be_blank → str.blank?
expect(obj).to be_valid → obj.valid?
Trade-offs
As readable and useful as Dynamic predicate math chairs can be, they do have some trade-offs. For example if you want to test for exact true or false results and another bigger problem is documentation, because Dynamic matters are generated on the fly, they have no documentation.
Higher-order matchers
All the matchers seen so far are primitives. Now, we are going to look at higher order matchers that is, matchers that you can pass other matchers into. With this technique, you can build up composed matchers that specify exactly the behavior you need.
Collections and strings
RSpec ships with six different matches for dealing with data structures:
| Matcher | Usage | Example |
|---|---|---|
| include | Checks that certain items are present (any order). | expect([1, 2, 3]).to include(2, 3) |
| start_with | Checks that items appear at the beginning. | expect([1, 2, 3]).to start_with(1, 2) |
| end_with | Checks that items appear at the end. | expect("foobar").to end_with("bar") |
| all | Checks that all elements satisfy a matcher. | expect([1, 3, 5]).to all be_odd |
| match | Matches a data structure exactly (order matters for arrays). | expect([1, 2]).to match([be_odd, be_even]) |
| contain_exactly | Checks that a collection has exactly these items (order doesn't matter). | expect([1, 2, 3]).to contain_exactly(3, 2, 1) |
All of these matchers also work with strings, with a few minor differences.
Include
The include matcher is one of the most flexible. By using include rather than a structure matcher like eq or match, you can specify just the elements you care about. The collection can contain unrelated items, and your test will still pass.
At its simplest, the include matcher works on any object with an include? method. Strings and arrays both support this method.
expect('a string').to include('str')
expect([1, 2, 3]).to include(3)
hash = { name: 'Harry Potter', age: 17, house: 'Gryffindor' }
expect(hash).to include(:name)
expect(hash).to include(age: 17)
It also accepts a variable number of arguments so that you can specify multiple substrings, array items, hash keys or key-value pairs:
expect('a string').to include('str', 'ing')
expect([1, 2, 3]).to include(3, 2)
expect(hash).to include(:name, :age)
expect(hash).to include(name: 'Harry Potter', age: 17)
This works well, but there is a gotcha related to variable numbers of items. Consider this example:
expecteds = [3, 2]
expect([1, 2, 3]).to include(expecteds)
# failure message
expected [1, 2, 3] to include [3, 2]
# possible solutions:
expect([1, [3, 2]]).to include([3, 2])
expect([1, 2, 3]).to include(*expecteds)
start_with and end_with
These two matchers are useful when you care about the content of a string or a collection at the start or end but don’t care about the rest.
expect('a string').to start_with('a str').and end_with('ng')
expect([1, 2, 3]).to start_with(1).and end_with(3)
# use separately
expect([1, 2, 3]).to start_with(1, 2)
expect([1, 2, 3]).to end_with(2, 3)
# aliases and compounding
expect(['list', 'of', 'words']).to start_with(
a_string_ending_with('st')
).and end_with(
a_string_starting_with('wo')
)
all
The all matcher is somewhat of an oddity: it is the only built-in matter that is not a verb, and it is the only one that always takes another matcher as an argument:
numbers = [1, 2, 3]
expect(numbers).to all be_even
This expression does exactly what it says: it expects all the numbers in the array to be even.
One gotcha to be aware of is that, like Enumerable#all?, this matcher passes against an empty array. This can lead to surprises. Example:
def self.evens_up_to(n = 0)
0.upto(n).select(&:odd?)
end
expect(evens_up_to).to all be_even
Our expectation didn’t fail and we forgot to pass an argument to evens_up_to
RSpec::Matchers.define_negated_matcher :be_non_empty, :be_empty
expect(evens_up_to).to be_non_empty.and all be_even
We’re using another RSpec feature, define_negated_matcher, to create a new be_non_empty matcher that’s the opposite of be_empty.
Now, the expectation correctly flags the broken method as failing:
expected `[].empty?` to return false, got true
Match
If you call JSON or XML APIs, you often end up with deeply nested arrays and hashes.
As you did with eq, you provide a data structure that’s laid out like the result you’re expecting. match is more flexible
children = [
{ name: 'Coen', age: 6 },
{ name: 'Daphne', age: 4 },
{ name: 'Crosby', age: 2 }
]
expect(children).to match [
{ name: 'Coen', age: a_value > 5 },
{ name: 'Daphne', age: a_value_between(3, 5) },
{ name: 'Crosby', age: a_value < 3 }
]
#it works with strings too
expect('a string').to match(/str/)
expect('a string').to match('str')
Contain_exactly
We’ve seen that match checks data structures more loosely than eq; contain_exactly is even looser. The difference is that match requires a specific order, whereas contain_exactly ignores ordering.
expect(children).to contain_exactly(
{ name: 'Daphne', age: a_value_between(3, 5) },
{ name: 'Crosby', age: a_value < 3 },
{ name: 'Coen', age: a_value > 5 }
)
expect(children).to contain_exactly(
{ name: 'Crosby', age: a_value < 3 },
{ name: 'Coen', age: a_value > 5 },
{ name: 'Daphne', age: a_value_between(3, 5) }
)
Which collection matcher should I use?
With a half dozen collection matches to pick from, you may wonder which one is the best for your situation. In general, we recommend you use the loosest matter that still specifies the behavior you care about.
Using a loose matcher makes your specs less brittle: it prevents incidental details from causing an unexpected failure.
Quick reference for the different uses:
Block matchers
With all the expectations we have seen so far, we have past regular Ruby objects into expect:
expect(3).to eq(3)
this is fine for checking properties of your data. but sometimes you need to check properties of a piece of code. for example, perhaps a certain piece of code is supposed to raise an exception.
```ruby
expect { raise 'boom' }.to raise_error('boom')
Rsbec will run the block and watch for the specific side effects you specify: exceptions, mutating variables, I/O and so on.
Raising and throwing
R s p e c provides matters for both of the situations: that are properly named race error and throw SYM
race error
first, let’s look at race error also known as race exception. this matter is very flexible, supporting multiple forms:
race error with no arguments match if any error is raised race error( some error class) matches if some error class or soup class is raised
race error(‘message error’) matches if an error is raised with a message exactly equal to a giving a string
raise error(/some Rejects/) matches if an error is raised with a message matching a given pattern
you can also combine these criteria if the class and the message are important
raise_error(SomeErrorClass, “some message”) • raise_error(SomeErrorClass, /some regex/) • raise_error(SomeErrorClass).with_message(“some message”) • raise_error(SomeErrorClass).with_message(/some regex/)
expect {
'hello'.world
}.to raise_error(an_object_having_attributes(name: :world))
There are a couple of caches with race error that can lead can lead to false positives. furious, race error with no arguments will match any error and it cannot tell the difference between exceptions you did or did not mean to throw.
for example if you rename a method but forget to update your spec on my Ruby will throw a effort ever. and over serious race Arrow will swallow this exception and respect will pass.
always include some kind of detail – either I specific custom ever class or a snippet from the message – that is unique to the specific race statement you are testing
throw symbol exceptions are designed for, well, exceptional situation such as an error in a program logic. they are not suited for everyday control flow, so just jumping out of a deeply nasty nasty look or a methyl. for situation like this, Ruby provides the Federal construct.
expect { throw :found }.to throw_symbol(:found)
expect { throw :found, 10 }.to throw_symbol(:found, a_value > 9)
Yielding
blocks are one of rubies most distinctive features. they allow you to pass around little chunks of code using an easy to read syntax
def self.just_yield
puts "[just_yield] about to yield"
yield
puts "[just_yield] after yield"
end
RSpec.describe "yield_control demo" do
it "shows the flow" do
expect { |block_checker|
puts "[expect block] calling just_yield with block_checker"
just_yield(&block_checker)
puts "[expect block] returned from just_yield"
}.to yield_control
end
end
#output
[expect block] calling just_yield with block_checker
[just_yield] about to yield
[just_yield] after yield
[expect block] returned from just_yield
You can also add with these Guild arguments, no arguments and successive arguments
Mutation
here we use the change matcher that will help you specify the sort of mutation you are expecting
array = [1, 2, 3]
expect { array << 4 }.to change { array.size }
The matcher performs the following actions in turn:
- Run your change block and store the result, array.size, as the before value
- Run the code under test, array « 4
- Run your change block a second time and store the result, array.size, as the after value
- Pass the expectation if the before and after values are different
This expectation checks whether or not the expectation changed
If you need to be more specific and highlight the amount of the change you can use:
Specifically, you can use by, by_at_least, or by_at_most to specify the amount of the change:
expect { array.concat([1, 2, 3]) }.to change { array.size }.by(3)
expect { array.concat([1, 2, 3]) }.to change { array.size }.by_at_least(2)
expect { array.concat([1, 2, 3]) }.to change { array.size }.by_at_most(4)
and also we have the front and two if you want to know the exact before and after values
expect { array << 4 }.to change { array.size }.from(3)
expect { array << 5 }.to change { array.size }.to(5)
expect { array << 6 }.to change { array.size }.from(5).to(6)
expect { array << 7 }.to change { array.size }.to(7).from(6)
Summary of this chapter:
Primitive matchers
| Concept | Usage | Example |
|---|---|---|
| Equality (eq) | Value equality: two objects that mean the same. | expect(42).to eq 42.0 |
| Identity (equal) | Object identity: same object reference. | expect(a).to equal(a) |
| Hash key equality (eql) | Equality as defined by Hash key rules. | expect(:a).to eql(:a) |
| Aliases | an_object_eq_to → eqan_object_equal_to → equalan_object_eql_to → eql |
expect(x).to an_object_eq_to(y) |
| Truthiness | Checks truthy/falsey values. | expect(true).to be_truthy |
| Operator comparison | Delegates to Ruby’s operators. | expect(5).to be > 3 |
| Delta & Range | Approximate numeric comparisons. | expect(3.14).to be_within(0.01).of(3.15) |
| Dynamic predicates | Calls Ruby predicate methods. | expect([]).to be_empty |
Recommendation: When in doubt, use eq. Value equality is the one you need most often. |
||
Higher order matchers
| Matcher | Usage | Example |
|---|---|---|
| include | Requires certain items to be present (any order). | expect([1,2,3]).to include(2,3) |
| start_with | Checks items at the beginning. | expect([1,2,3]).to start_with(1) |
| end_with | Checks items at the end. | expect("hello").to end_with("lo") |
| all | Applies a matcher to all elements. | expect([1,3,5]).to all be_odd |
| match | Matches against a pattern (array/hash/string/regex). Requires order. | expect({a:1,b:2}).to match(a: be > 0, b: be < 3) |
| contain_exactly | Checks that only the given items are present, ignoring order. | expect([1,2,3]).to contain_exactly(3,1,2) |
Recommendation: Prefer the loosest matcher that still specifies the behavior you care about. For example, use contain_exactly when order doesn’t matter to avoid brittle specs. Match when order matter |
||
Block matchers
| Matcher | Usage | Example |
|---|---|---|
| raise_error | Asserts exceptions raised in a block. |
expect { 1/0 }.to raise_error(ZeroDivisionError)expect { foo }.to raise_error("bad")expect { bar }.to raise_error(/pattern/)
|
| yield_control | Checks that a block yields. | expect { |b| obj.call(&b) }.to yield_control |
| change | Asserts that a block mutates state. |
expect { arr << 1 }.to change { arr.size }.by(1)expect { arr << 2 }.to change { arr.size }.from(1).to(2)
|
Recommendation: Use change when you care about mutations, yield when testing block semantics, and always make raise_error specific to avoid false positives. |
||
Part IV — Chapter 12. Creating custom matchers.
Creating custom matchers
In the previous chapter, we took a tour of the matchers that ship with RSpec. We can be productive with them on simpler projects, they may be or what you need.
Eventually, though, you are going to hit the limits of the built-in matchers. Because they are meant for testing general purpose Ruby code, they require you to speak in Ruby terms rather than your projects terms.
For example please take a look at the next expectations:
Without custom matchers:
expect(art_show.tickets_sold.count).to eq(0)
expect(u2_concert.tickets_sold.count).to eq(u2_concert.capacity)
With custom matchers
expect(art_show).to have_no_tickets_sold
expect(u2_concert).to be_sold_out
We have added to custom matchers have_no_tickets_sold and be_sold_out, so that we can describe the behavior in terms of events and tickets. These are the terms that the rest of the project team would use.
This reminds me of this Martin Fowler talk: https://www.youtube.com/watch?v=pGB5g-Do3qI
He cites an exercise by Kent Beck, where he asked team members: “Describe how the system works using only four objects.” If they all chose the same objects, he could deduce that the team had good coherence. Otherwise, if they picked different objects, it showed that the team lacked cohesion.
When we write clear, easy to use custom matchers, you gain several benefits:
- you stand a greater chance of building what your stakeholders want
- you reduce the cost of API changes (because you need only update your match)
- you can provide better failure messages when something
- and you improve the test output, example:
Without custom matchers:
expected: 0
got: 2
(compared using ==)
expected: 10000
got: 9900
(compared using ==)
With custom matchers
expected #<Event "Art Show" (capacity: 100)> to have no tickets sold, but had 2
expected #<Event "U2 Concert" (capacity: 10000)> to be sold out, but had 100 unsold tickets
Not only does this report to speak out the main language, it also provides additional details such as what specific events we are testing here.
Delegating to existing matchers using helper methods.
We are going to start with a technique we have already used to keep your code organized: helper methods
This is a test that we used when we built the expense tracker app
expect(ledger.expenses_on('2017-06-10')).to contain_exactly(
a_hash_including(id: result_1.expense_id),
a_hash_including(id: result_2.expense_id)
)
This matcher got the job done. Notice, though, how it expresses the expectation in terms of Ruby objects: hashes and IDs.
Let’s use the main language of the project:
expect(ledger.expenses_on('2017-06-10')).to contain_exactly(
an_expense_identified_by(result_1.expense_id),
an_expense_identified_by(result_2.expense_id)
)
# spec/spec_helper.rb
module ExpenseTrackerMatchers
def an_expense_identified_by(id)
a_hash_including(id: id)
end
end
RSpec.configure do |config|
config.include ExpenseTrackerMatchers
We are delegating to another matcher but there is a gotcha that may bring about a false positive so let’s make this match more robust.
This data structure would make the test pass
{
id: 1,
email: 'john.doe@example.com',
role: 'admin'
}
# let’s add the payee, amount and date by using compounding “.and”
def an_expense_identified_by(id)
a_hash_including(id: id).and including(:payee, :amount, :date)
end
RSpec allows you to create aliases for different matchers, this is how you can define them:
Example of RSpec built-in:
# a_value_within as an alias of the be_within matcher
expect(results).to start_with a_value_within(0.1).of(Math::PI)
Inside of the file 12-creating-custom-matchers/05/custom_matchers.rb
RSpec::Matchers.alias_matcher :an_admin, :be_an_admin
# will produce
>> be_an_admin.description
=> "be an admin"
>> an_admin.description
=> "an admin"
The alias_matcher method can also take a block:
RSpec::Matchers.alias_matcher :an_admin, :be_an_admin do |old_description|
old_description.sub('be an admin', 'a superuser')
end
# will produce
>> an_admin.description
=> "a superuser"
Also you can create negating matchers
From this:
expect(correct_grammar).to_not split_infinitives
To this
expect(correct_grammar).to avoid_splitting_infinitives
RSpec::Matchers.define_negated_matcher :avoid_splitting_infinitives, :split_infinitives
As with alias_matcher, you pass the name of the new matcher, followed by the old one. The avoid_splitting_infinitives matcher will now behave as the negation of split_infinitives.
Using the matcher DSL.
Let’s go back to the expense tracker app with built and let’s say that we are going to build a custom have_a_balance_of matcher that helps with expectations
expect(account).to have_a_balance_of(30)
There are two ways to build a matcher like the one we just show
- Using a master DSL
- Creating a ruby class (any Ruby class can define a matcher, if it implements the matter protocol)
Let’s start with the matcher DSL
To define a matcher using the DSL, we call RSpec::Matchers.define, passing the matcher name and a block containing the matcher definition:
RSpec::Matchers.define :have_a_balance_of do |amount|
match { |account| account.current_balance == amount }
end
The outer block receives any arguments passed to the matcher. When a spec calls have_a_balance_of(amount), RSpec will pass the amount into this block.
The match method defines the actual match/no-match logic. The inner block receives the subject of the expectation (the account), and returns a truthy value if the account balance matches the expected amount.
Here’s the output that it produces when a spec fails:
1) `have_a_balance_of(amount)` fails when the balance does not match
Failure/Error: expect(account).to have_a_balance_of(35)
expected #<Account name="Checking"> to have a balance of 35
# ./spec/initial_account_spec.rb:17:in `block (2 levels) in <top
The failure message tells us that the account should have had a balance of 35. But it doesn’t say what the actual balance was.
it reminds me to the phrase “These two methods matches? and failure_message are all you need to define a simple matcher.” in chapter 10. Let’s add the failure_message
RSpec::Matchers.define :have_a_balance_of do |amount|
match { |account| account.current_balance == amount }
➤ failure_message { |account| super() + failure_reason(account) }
➤ failure_message_when_negated { |account| super() + failure_reason(account) }
private
def failure_reason(account)
", but had a balance of #{account.current_balance}"
end
end
Now this new matcher will work with expect(...).to(...) and for expect(...).not_to(...)
See the next failure message once we added these 2 new methods:
1) `have_a_balance_of(amount)` fails when the balance does not match
Failure/Error: expect(account).to have_a_balance_of(35)
expected #<Account name="Checking"> to have a balance of 35, but had a balance of 30
# ./spec/initial_account_spec.rb:17:in `block (2 levels) in <top
If we need to add a fluent interface like:
• be_within(0.1).of(50) • change { … }.from(x).to(y) • output(/warning/).to_stderr
We can do it by defining again starting with the matcher:
expect(account).to have_a_balance_of(10).as_of(Date.new(2017, 6, 12))
And within out matcher file we add the as_of()
RSpec::Matchers.define :have_a_balance_of do |amount|
➤ chain(:as_of) { |date| @as_of_date = date }
match { |account| account_balance(account) == amount }
failure_message { |account| super() + failure_reason(account) }
failure_message_when_negated { |account| super() + failure_reason(account) }
private
def failure_reason(account)
", but had a balance of #{account_balance(account)}"
end
def account_balance(account)
if @as_of_date
account.balance_as_of(@as_of_date)
else
account.current_balance
end
end
end
Defining a matcher class
If we need a little more control or my prefer to define the matter in the most explicit way possible we need to create a ruby class matcher.
class HaveABalanceOf
include RSpec::Matchers::Composable
def initialize(amount)
@amount = amount
end
def as_of(date)
@as_of_date = date
self
end
def matches?(account)
@account = account
values_match?(@amount, account_balance)
end
def description
if @as_of_date
"have a balance of #{description_of(@amount)} as of #{@as_of_date}"
else
"have a balance of #{description_of(@amount)}"
end
end
def failure_message
"expected #{@account.inspect} to #{description}" + failure_reason
end
def failure_message_when_negated
"expected #{@account.inspect} not to #{description}" + failure_reason
end
private
def failure_reason
", but had a balance of #{account_balance}"
end
def account_balance
if @as_of_date
@account.balance_as_of(@as_of_date)
else
@account.current_balance
end
end
end
Let’s walk through:
RSpec integration, within matcher.rb
module AccountMatchers
def have_a_balance_of(amount)
HaveABalanceOf.new(amount)
end
end
RSpec.configure do |config|
config.include AccountMatchers
end
However, in certain situations the custom matcher class is a better fit:
• If your matcher is going to be used hundreds or thousands of times, writing your own class avoids a bit of extra overhead inherent in how the DSL is evaluated. • Some teams prefer more explicit code. • If you leave out the RSpec::Matchers::Composable mixin, your matcher won’t have any dependencies on RSpec and will work in non-RSpec contexts.
Part V — RSpec mocks.
A robust test suite will run fast, be deterministic, and cover all essential code paths.
Unfortunately, dependencies often get in the way of these goals. We can’t reliably test code while it is integrated with other libraries or systems. Test doubles, including mock objects allow you to tightly control the environment in which your test run.
Part V — Chapter 13. Understanding test doubles.
In this chapter we will see:
- How doubles can isolate your code from your dependencies, the difference between mocks, stubs, spies and null objects.
- How to add test double behavior to an existing Ruby object.
- and how to keep your doubles and your real objects in sync.
In movies, a stunt double stands in for an actor, absorbing a punch or a fall when the actor cannot or should not do so. In test frameworks like RSpec, test double fulfills the same role. It stands in for another object doing testing.
When we wrote the API unit specs for our expense tracker app, we treated the storage engine layer as if it were behaving exactly how we needed it, even though that the layer had not been written yet.
This ability to isolate parts of your system while you are testing it is super powerful. With test doubles, we can:
- Exercise hard to reach code paths, such as ever handling and reliable third-party service.
- Write specs for a layer of your system before you have built it its dependencies.
- Use an API while you are still designing it so that you can fix problems with the design before the implementation.
- Demonstrate how a component Works relative to its neighbors.
Types of test doubles:
Test doubles have two characteristics one is the usage mode (what you are using it for and what you are expecting to) and the other is how the double is created, the origin.
Here are the usage modes:
- Stub: returns canned responses, avoiding any meaningful computation or I/O.
- Mock: expects a specific messages: will raise an error if it doesn’t receive them by the end of the example.
- Null Object: a benign test double that can stand in for any object: returns itself in response to any message.
- Spy: records the message it receives so that you can check that later.
Now here are the origins:
-
Pure double: a double whose behavior comes entirely from the test framework; this is what people normally think of when they talk about mock objects.
-
Partial double: an existing Ruby object that takes on some tests that will behavior, it’s an interface is a mixture of real and fake implementations.
-
Verifying double totally fake like a pure double, but constraints it’s interface based on a real object like a partial double; provides a safer test double by verifying that it matches the API.
-
Stubbed constant: a ruby constant such as a class or module name, which you create, remove or replace for a single test.
Any given test of what we have both on our origin and a usage mode and you can mix them for instance have a pure double acting as a stub, or a verifying double acting as a spy.
Usage mode: mocks, stubs and spies.
Generic test double
In an irb session call mock RSpec library. RSpec’s double method creates a generic test double that you can use in any mode.
irb(main):001> require 'rspec/mocks/standalone'
=> true
irb(main):002> ledger = double
=> #<Double (anonymous)>
This double acts like an ordinary Ruby object. As you send messages to it (in other words, call methods on it), it will accept some messages and reject others.
The difference is that a generic double gives you more debugging information than a regular Ruby object.
irb(main):003> ledger.record(an: :expense)
/Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rspec-support-3.13.4/lib/rspec/support.rb:110:in 'block in <module:Support>': #<Double (anonymous)> received unexpected message :record with ({an: :expense}) (RSpec::Mocks::MockExpectationError)
When we sent this message (.record), the double raised an exception. Doubles are strict by default: they will reject all messages except the ones you’ve specifically allowed.
RSpec shows both the message name and arguments we sent to our double; this is already more information than a typical Ruby NoMethodError.
We can get a little more details in the error message by naming the role the double plays:
irb(main):004> ledger = double('Ledger')
=> #<Double "Ledger">
irb(main):005> ledger.record(an: :expense)
/Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rspec-support-3.13.4/lib/rspec/support.rb:110:in 'block in <module:Support>': #<Double "Ledger"> received unexpected message :record with ({an: :expense}) (RSpec::Mocks::MockExpectationError)
This extra information comes in handy when you’re using multiple doubles in the same example.
This same double method can create any of the other kinds of test doubles you’ll use in your specs: stubs, mocks, spies, and null objects.
Stubs
Stubs are simple. They return preprogrammed, canned responses. Stubs are best for when you’re simulating query methods that is, methods that return a value but don’t perform side effects.
The simplest way to define a stub is to pass a hash of method names and return values to the double method:
irb(main):006> http_response = double('HTTPResponse', status: 200, body: 'OK')
=> #<Double "HTTPResponse">
irb(main):007> http_response.status
=> 200
irb(main):008> http_response.body
=> "OK"
An alternative, you can perform these two steps for creating the stub and setting up the canned messages:
irb(main):009> http_response = double('HTTPResponse')
=> #<Double "HTTPResponse">
irb(main):010> allow(http_response).to receive_messages(status: 200, body: 'OK')
=> {status: 200, body: "OK"}
irb(main):011> http_response.status
=> 200
irb(main):012> http_response.body
=> "OK"
Stubs watch for specific messages and return the same value each time they receive a given message. They don’t act differently based on their arguments.
irb(main):013> http_response.status(:args, :are, :ignored)
=> 200
irb(main):014> http_response.body(:blocks, :are, :also) { :ignored }
=> "OK"
Stubs help with a specific kind of behavior—the kind that can be verified just by looking at return values.
- Query data from a dependency
- Perform a computation on that data
- Return a result
Your specifications can verify the object’s behavior simply by examining the return value in step 3. The only responsibility of the stub is to provide a suitable response to the query in step 1.
Mocks
With these, it’s not a return value that you care about, but rather a side effect. Here’s a typical sequence:
- Receive an event from the system
- Make a decision based on that event
- Perform an action that has a side effect
For instance, a chat bot’s Reply feature may receive a text message, decide how to reply, and then post a message in the chat room.
To test this behavior, it’s not enough for your test double to provide a fixed return value at step 3. It needs to make sure the object triggered the side effect of posting a message correctly.
To use a mock object, you’ll pre-program it with a set of messages it’s supposed to receive. These are called message expectations. By combining the expect method with a matcher:
irb(main):015>ledger = double('Ledger')
irb(main):016> expect(ledger).to receive(:record)
=> #<RSpec::Mocks::MessageExpectation #<Double "Ledger">.record(any arguments)>
Once you’ve created a mock object, you’ll typically pass it into the code you’re testing. At the end of each RSpec example, RSpec verifies that all mocks received their expected messages.
irb(main):016> RSpec::Mocks.verify
(irb):15:in '<main>': (Double "Ledger").record(*(any args)) (RSpec::Mocks::MockExpectationError)
expected: 1 time with any arguments
received: 0 times with any arguments
Because the mock Ledger didn’t receive the messages it was expecting, it raises a MockExpectationError message.
You can also specify the opposite behavior:
irb(main):017> expect(ledger).not_to receive(:reset)
=> #<RSpec::Mocks::MessageExpectation #<Double "Ledger">.reset(any arguments)>
irb(main):018> ledger.reset
/Users/dominiclizarraga/.rbenv/versions/3.4.2/lib/ruby/gems/3.4.0/gems/rspec-support-3.13.4/lib/rspec/support.rb:110:in 'block in <module:Support>': (Double "Ledger").reset(no args) (RSpec::Mocks::MockExpectationError)
expected: 0 times with any arguments
received: 1 time
We see a failure because the mock object received a message it was specifically expecting not to receive.
Null objects
The test doubles you’ve defined so far are strict: they require you to declare in advance what messages are allowed. But when your test double needs to receive several messages, having to spell each one out can make your tests brittle, you may want a test double that’s a little more forgiving.
You can convert any test double to a null object by calling as_null_object on it:
irb(main):019> yoshi = double('Yoshi').as_null_object
=> #<Double "Yoshi">
irb(main):020> yoshi.eat(:apple)
=> #<Double "Yoshi">
This type of null object is known as a black hole; it responds to any message sent to it, and always returns itself.
irb(main):021> yoshi.eat(:apple).then_shoot(:shell).then_stomp
=> #<Double "Yoshi">
If you have a ChatBot class that interacts with a room and a user, you may want to test these collaborations separately. While you’re focusing on the user related specs, you can use a null object for the room.
Spies
One downside of traditional mocks is that they disrupt the normal Arrange/Act/Assert sequence you’re used to in your tests.
See the next code:
irb(main):022* class Game
irb(main):023* def self.play(character)
irb(main):024* character.jump
irb(main):025* end
irb(main):026> end
=> :play
irb(main):027> mario = double('Mario')
=> #<Double "Mario">
irb(main):028> expect(mario).to receive(:jump)
=> #<RSpec::Mocks::MessageExpectation #<Double "Mario">.jump(any arguments)>
irb(main):029> Game.play(mario)
=> nil
It feels a bit backwards to have to assert before acting. Spies are one way to restore the traditional flow. All you have to do is change the receive expectation to have_received.
irb(main):030> mario = double('Mario').as_null_object
=> #<Double "Mario">
irb(main):031> Game.play(mario)
=> #<Double "Mario">
irb(main):032> expect(mario).to have_received(:jump)
=> nil
When you spy on objects with have_received, you’ll either need to use null objects or explicitly allow the expected messages
irb(main):033> mario = double('Mario')
=> #<Double "Mario">
irb(main):034> allow(mario).to receive(:jump)
=> #<RSpec::Mocks::MessageExpectation #<Double "Mario">.jump(any arguments)>
irb(main):035> Game.play(mario)
=> nil
irb(main):036> expect(mario).to have_received(:jump)
=> nil
# another way is using `spy` keyword which is an alias
irb(main):037> mario = spy('Mario')
=> #<Double "Mario">
irb(main):038> Game.play(mario)
=> #<Double "Mario">
irb(main):039> expect(mario).to have_received(:jump)
=> nil
Here, we used a chatGPT explanation for null obejcts and spies 🤖
Scenario: ChatBot
class ChatBot
def initialize(room)
@room = room
end
def reply_to(message)
if message == "hi"
@room.post("hello 👋")
else
@room.post("🤔")
end
end
end
Null Object
Suppose you only care about testing how the bot decides what to say, not whether it really posted to the room.
Instead of stubbing every possible method on Room, we just use a null object:
RSpec.describe ChatBot do
it "returns a response without caring about the room" do
room = double("Room").as_null_object # accepts any message
bot = ChatBot.new(room)
bot.reply_to("hi")
# no error, even though we didn’t define room.post
end
end
as_null_object is useful when the collaborator is irrelevant to the test — it “swallows” all messages without complaints.
Spy
Now let’s say we do care that room.post got called correctly.
Using a spy, we can check after the action:
RSpec.describe ChatBot do
it "posts a greeting when user says hi" do
room = spy("Room")
bot = ChatBot.new(room)
bot.reply_to("hi")
expect(room).to have_received(:post).with("hello 👋")
end
end
Notice the flow:
Arrange: create spy
Act: call method
Assert: verify with have_received
This keeps the familiar Arrange–Act–Assert pattern, unlike mocks where you must set the expectation before acting.
Combining as_null_object and Spies
Sometimes, you want an object that:
-
Accepts any call (like a null object)
-
But you can still inspect later what happened (like a spy)
That’s exactly what spy (or double(…).as_null_object + have_received) gives you.
room = double("Room").as_null_object
bot = ChatBot.new(room)
bot.reply_to("bye")
expect(room).to have_received(:post).with("🤔")
# or equivalently:
room = spy("Room")
bot = ChatBot.new(room)
bot.reply_to("bye")
expect(room).to have_received(:post).with("🤔")
🔑 Key Takeaways
Null Object (as_null_object): ignores everything, returns itself → great when collaborator doesn’t matter.
Spy (spy or have_received): records what happened → great when you want to assert after-the-fact.
spy(“Name”) is basically shorthand for double(“Name”).as_null_object.
chatGPT session ended.
Origins: pure, partial, and verifying doubles
Now that we have seen the different usage modes of the tests doubles, let’s look at where they come from.
Pure doubles
All of the test doubles you have written so far in this chapter are pure doubles: they are purpose-built by RSpec mocks and consist entirely of behavior you add to them. You can pass them into your project code just as if they were the real thing.
Pure doubles are flexible and easy to get started with. They are best for testing code where you can pass in dependencies. Unfortunately, real world projects are not always so test-friendly, and you will need to turn to more powerful techniques.
Partial doubles
Sometimes, the code you are testing does not give you an easy way to inject dependencies, a hard coded class name may be looking three layers deep in the API you are calling. For instance, a lot of Ruby projects called Time.now without providing a way to override the behavior during testing.
To test these kinds of codebases, you can use a partial double. This add mocking and stubbing behavior to an existing Ruby objects. That means any object in your system can be a partial double. All you have to do is expect or allow a specific message.
=> true
irb(main):004> random = Random.new
=> #<Random:0x0000000122814a20>
irb(main):005> allow(random).to receive(:rand).and_return(0.1234)
=> #<RSpec::Mocks::MessageExpectation #<Random:0x0000000122814a20>.rand(any arguments)>
irb(main):006> random.rand
=> 0.1234
In this snippet, you have created an instance of a Ruby random number generator, and then replace its rand method with one that returns a can value.
You can also use a partial double as a spy using the expect().to have_received form
irb(main):009> allow(Dir).to receive(:mktmpdir).and_yield('/path/to/tmp')
=> #<RSpec::Mocks::MessageExpectation #<Dir (class)>.mktmpdir(any arguments)>
irb(main):010> Dir.mktmpdir { |dir| puts "Dir is: #{dir}" }
Dir is: /path/to/tmp
=> nil
irb(main):011> expect(Dir).to have_received(:mktmpdir)
=> nil
You could permit any message using a spy or as_null_object or explicitly allow just the message you want. With partial doubles, you can only do that later.
RSpec will revert it all your changes at the end of each example. there will be object will go back to its original behavior.
Since we are experimenting in stand-alone mode we need to call the tear down explicitly to clean up what happened.
irb(main):012> RSpec::Mocks.teardown
=> #<RSpec::Mocks::RootSpace:0x0000000121f74e10>
irb(main):013> random.rand
=> 0.13639968906104905
irb(main):014> random.rand
=> 0.30073063313880466
Test doubles have short lifetimes
RSpec tears down all your test doubles at the end of each example. That means they wont to play well with RSpec features that leave outside the typical per-examples, such as before(:context) hooks. You can work around some of these limitations with a method name with_temporary_scope.
Partial doubles are useful but we consider them as a code smell, a superficial sign that might lead to a deeper design issue.
Verifying doubles
The upside of test doubles is that they can stand in for a dependency you do not want to track into your test. The downside is that the double and the dependency can drift out of sync with each other. Verifying doubles can protect you from this kind of drift.
While we wrote the expense tracker app we touch briefly on verifying doubles when we marked the Ledger class because it didn’t exist yet. Here is a simplified version
ledger = double('ExpenseTracker::Ledger')
allow(ledger).to receive(:record)
post '/expenses' do
expense = JSON.parse(request.body.read)
result = @ledger.record(expense)
JSON.generate('expense_id' => result.expense_id)
end
The Ledger class didn’t exist yet; the test double provided enough of an implementation for your routing specs to pass.
Consider what will happen if at some point you rename the Ledger#record method to Ledger#record_expense but forgot to update their routing code. Your specs would still pass, since they are still providing fake record method. But your code will fail in real world use, because it is trying to call a method that no longer exist. These kinds of false positives can kill confidence in your unit specs.
You avoided this drive in your expense tracker project by using a verifying double to do so, you call instance_double in place of double, passing the name of The Ledger class.
ledger = instance_double('ExpenseTracker::Ledger')
allow(ledger).to receive(:record)
With this double in place, RSpec checks that the real Ledger class (if it is loaded) actually response to the record message with the same signature. If you rename this method to record_expense, or add or remove arguments, your specs will correctly fail under your update your use of the method and your test double setup.
Use verifying doubles to catch problems earlier
Although your unit specs will have a false positive, you’re acceptance specs will still have cut this regression. That’s because they use the real versions of the objects, rather than counting on test doubles.
By using verifying doubles in your unit specs you get the best of both worlds. You will catch errora earlier and at less cost, while writing specs that behave correctly when APIs change.
RSpec gives you a few different ways to create verifying doubles, based on what it will use as an interface template for the double:
-
instance_double(‘SomeClass’): Constrains the double’s interface using the instance methods of SomeClass
-
class_double(‘SomeClass’): Constrains the double’s interface using the class methods of SomeClass
-
object_double(some_object): Constrains the double’s interface using the methods of some_object, rather than a class; handy for dynamic objects that use method_missing
Stubbed constants
Test doubles are all about controlling the environment your specs running: what classes are available, how certain methods behaves, and so on. a key piece of that environment is the set of Ruby constant available to your code.
For instance, password hashing algorithms are slow by design for security reasons, but you may want to pick them up during testing please see the next code snippet
class PasswordHash
COST_FACTOR = 12
# ...
end
stub_const('PasswordHash::COST_FACTOR', 1)
You can use stub_const to do a number of things:
• Define a new constant • Replace an existing constant • Replace an entire module or class (because these are also constants) • Avoid loading an expensive class, using a lightweight fake in its place
Sometimes controlling your test environment means removing an existing constant instead of stopping one. For example, if you’re writing a library that works either with or without ActiveRecord, you can hide the ActiveRecord constant for a specific example:
Hiding the ActiveRecord constant like this will cut off access to the entire module. Including any nested constants like ActiveRecord::Base. Your code won’t be able to accidentally use ActiveRecord. Just as with partial doubles, any constants you have changed or hidden will be restored at the end of each example.
hide_const('ActiveRecord')
We have discussed the differences between stubs, spies and null_objects. In particular we saw how they deal with the following situations:
- Receiving expected messages
- Receiving unexpected messages
- Not receiving expected messages
We also looked at the different ways to create test doubles.. pure doubles are entirely fake, whereas partial doubles are real Ruby objects that have fake behavior at it. Verifying doubles fall in between and have the advantages of both with a few of the downsides of either.
Part V — Chapter 14. Customizing test doubles.
In this chapter we are going to see how to return, raise, yield a value from our test double. How to supply custom behavior, how to ensure that the double test is calling the right arguments and how many times it calls it and in the right order.
Configuring responses
Since a test double is meant to standing for a real object, it needs to act like one. You need to be able to configure how it responds to the code calling it.
When you allow or expect a message on a test double without specifying how it responds, RSpec provides a simple implementations that just returns nil. Your test doubles will often need to do something more interesting: return a given value, raise an error, yield to a block, or throw a symbol.
allow(double).to receive(:a_message).and_return(a_return_value)
allow(double).to receive(:a_message).and_raise(AnException)
allow(double).to receive(:a_message).and_yield(a_value_to_a_block)
allow(double).to receive(:a_message).and_throw(:a_symbol, optional_value)
allow(double).to receive(:a_message) { |arg| do_something_with(arg) }
# These last two are just for partial doubles:
allow(object).to receive(:a_message).and_call_original
allow(object).to receive(:a_message).and_wrap_original { |original| }
People new to rspec are often surprise at the behavior of expect on a partial double
expect(some_existing_object).to receive(:a_message)
Doesn’t just set up an expectation. it also changes the behavior of an existing object. Calls to some_existing_object.message will return nil and do nothing else. If you want to add a message expectation while retaining the original implementation, you will need to use and_call_original
Returning multiple values
We previously used and_return keyword when we set up our test double to return the same canned expense item each time it received the record message. Sometimes you need to stubbed method to do something more sophisticated that return the same value every time it is called. You might want to return one value for the first call, and a different one for the second call and so on.
>> allow(random).to receive(:rand).and_return(0.1, 0.2, 0.3)
=> #<RSpec::Mocks::MessageExpectation #<Double "Random">.rand(any arguments)>
>> random.rand
=> 0.1
>> random.rand
=> 0.2
>> random.rand
=> 0.3
>> random.rand
=> 0.3
>> random.rand
=> 0.3
Here we give three return values, and they rand method returns each one in sequence.
Yielding multiple values
Blocks are ubiquitous in Ruby, and sometimes your test doubles will need to stand in for it interface that uses blocks. The aptly name and_yield method will configure your double to yield values
extractor = double('TwitterURLExtractor')
allow(extractor).to receive(:extract_urls_from_twitter_firehose)
.and_yield('https://rspec.info/', 93284234987)
.and_yield('https://github.com/', 43984523459)
.and_yield('https://pragprog.com/', 33745639845)
We chain together extract_urls_from_twitter_firehose three and_yield calls. When the code we are testing calls with a block, the method will yield the block three times. Each time, the block we receive a URL and a numeric to it.
Raising exceptions flexibly
When you’re testing exception handling code, you can raise exceptions from your test doubles using the and_raise modifier. This method has a flexible API that mirrors Ruby Ray’s method.
In the examples we have shown so far, we’ve been working with pure test doubles. These doubles have to be told exactly how to respond, because they don’t have an existing implementation to modify.
allow(dbl).to receive(:msg).and_raise(AnExceptionClass)
allow(dbl).to receive(:msg).and_raise('an error message')
allow(dbl).to receive(:msg).and_raise(AnExceptionClass, 'with a message')
an_exception_instance = AnExceptionClass.new
allow(dbl).to receive(:msg).and_raise(an_exception_instance)
Partial doubles are different. Since they begin as an real object with a real method implementation, you can base the fake version on the real one.
Falling back to the original implementation
When you are using a partial double to replace a method, sometimes you only want to replace it conditionally. You may want to use a fake implementation for a certain parameters values but fall back on the real method the rest of the time.
In these cases, you can expect or allow twice: once like you normally would, and once we and_call_original to provide the default behavior.
# fake implementation for specific arguments:
allow(File).to receive(:read).with('/etc/passwd').and_raise('HAHA NOPE')
# fallback:
allow(File).to receive(:read).and_call_original
Here, we’ve used with(...) to constrain which parameter values this stub applies to.
Modifying the return value
Sometimes, you want to slightly change the behavior of the method you are stubbing, rather than replacing it outright. You may, for instance, need to modify its return value.
RSpec and and_wrap_original method, passing it a block containing your custom behavior. Your block will take the original implementation as an argument, which you can call at any time.
This is the technique to stub out a CustomerService API to return a subset of customers:
allow(CustomerService).to receive(:all).and_wrap_original do |original|
all_customers = original.call
all_customers.sort_by(&:id).take(10)
end
This technique can be handy for acceptance specs, where you want to test against a live service. If the vendor does not provide a test API that only returns a few records, you can call the real API and narrow down the records yourself. By working on just a subset of the data, your specs will remain snappy.
Tweaking arguments
You can also use and_wrap_original to tweak the arguments you pass into a method. Yhis technique comes in handy when the code you are testing uses a lot of hard coded values.
allow(PasswordHash).to receive(:hash_password)
.and_wrap_original do |original, cost_factor|
original.call(1)
end
Since both and_call_original and and_wrap_original need an existing implementation to call, they only make sense for partial doubles.
When you need more flexibility
So far, we have seen several different ways to customize how your test doubles behave. you can return or yield a specific sequence of values, race and exception, and so on.
Sometimes, though, the behavior you need is a slightly outside what this techniques provide. If you are not quite sure how to configure a double to do what you need, you can supply a block containing whatever custom Behavior you need. Simply pass the block to the latest method call in the received expression.
Here we are going to simulate an intermented Network failure while we are testing the request succeeds 75% of the time:
counter = 0
allow(weather_api).to receive(:temperature) do |zip_code|
counter = (counter + 1) % 4
counter.zero? ? raise(Timeout::Error) : 35.0
end
When your code calls the weather API, RSpec will run this block and depending on how many calls you’ve made, either return a value or raise a timeout exception
If your block gets any more complex than this example, you might be better off moving into its own Ruby class. Martin Fowler refers to this kind of standing as a fake. fakes particularly are useful when you need to preserve state across multiple method calls.
Setting constraints
Most of the test doubles you have created will accept any input. If you stub a method named jump with no other options, RSpec will use your scope whenever you’re code calls jump, jump(:with, :arguments), or jump { with_a_block }.
In this section we are going to look at ways to set constraints on a test double so that RSpec only uses it if your code calls it in a certain.
Constraining argument
You will often want to check that your code is calling a method with the correct parameters. To constrain what arguments your mock object will accept, add a call to with to your message exception
expect(movie).to receive(:record_review).with('Great movie!')
expect(movie).to receive(:record_review).with(/Great/)
expect(movie).to receive(:record_review).with('Great movie!', 5)
If your code calls the method with arguments that don’t match that constraint then the exception remains unsatisfied. RSpec will treat it the same as any other unmet expectation. In this example, we are using expect, meaning that RSpec will report a failure:
>> expect(movie).to receive(:record_review).with('Good')
=> #<RSpec::Mocks::MessageExpectation #<Double "Jaws">.record_review("Good")>
>> movie.record_review('Bad')
RSpec::Mocks::MockExpectationError: #<Double "Jaws"> received ↩
:record_review with unexpected arguments
expected: ("Good")
got: ("Bad")
« backtrace truncated »
If we had used allow instead, RSpec would have looked for another expectation that fit the passed-in arguments: (no failure raised!)
>> allow(imdb).to receive(:rating_for).and_return(3) # default
=> #<RSpec::Mocks::MessageExpectation #<Double "IMDB">.rating_for(any arguments)>
>> allow(imdb).to receive(:rating_for).with('Jaws').and_return(5)
=> #<RSpec::Mocks::MessageExpectation #<Double "IMDB">.rating_for("Jaws")>
>> imdb.rating_for('Weekend at Bernies')
=> 3
>> imdb.rating_for('Jaws')
=> 5
Your test doubles can require something as simple as a specific value, or as sophisticated as any custom logic you can devise.
Argument placeholders
When a message takes several arguments, you maker more about some than others. In the next example we are stubbing a shoppingcart add_product method that takes a name, a numeric id, and then vendor specific code. If we only care about the name, you can pass they worth anything as a placeholder for the others
expect(cart).to receive(:add_product).with('Hoodie', anything, anything)
You can also represent a sequence of anything placeholders with any_args
expect(cart).to receive(:add_product).with('Hoodie', any_args)
The counterpart to any_args is no_args:
expect(database).to receive(:delete_all_the_things).with(no_args)
Hashes and keyword arguments
Ruby APIs, especially ones written before Ruby 2.0 came out
class BoxOffice
def find_showtime(options)
# ...
end
end
box_office.find_showtime(movie: 'Jaws')
box_office.find_showtime(movie: 'Jaws', zip_code: 97204)
box_office.find_showtime(movie: 'Jaws', city: 'Portland', state: 'OR')
When you’re testing code that calls such a method, you can use RSpec’s hash_including to specify which keys must be present. All three of these find_showtime calls would match the following constraint:
expect(box_office).to receive(:find_showtime)
.with(hash_including(movie: 'Jaws'))
Flexible constraints like hash_including make your specs less brittle. Rather than having to give all the keys of your hash, you can give just the ones you care about. If the value of an unimportant key changes, your specs needn’t fail.
Ruby 2.0 added keyword arguments
class BoxOffice
def find_showtime(movie:, zip_code: nil, city: nil, state: nil)
# ...
end
end
The good news is that the hash_including constraint works just as well with keyword arguments as it does with old-style option hashes.
RSpec also provides a hash_excluding constraint to specify that a hash must not include a particular key
Custom logic
When you have written a bunch of constraints, you will inevitably find yourself repeating the same complex constraint in several specs. occasionally, you will need logic that’s too involve to express as a simple constraint. In both of these situations, you can supply your own custom logic
For example, if you have several specs that shoudl call find_showtime with cities in Oregon, you can wrap this constraint in a custom rspec matter:
RSpec::Matchers.define :a_city_in_oregon do
match { |options| options[:state] == 'OR' && options[:city] }
end
# usage of .with
expect(box_office).to receive(:find_showtime).with(a_city_in_oregon)
You can constrain arguments using an ordinary Ruby value, a regular expression, one of RSpec-mocks provided constraints or any built-in or custom matcher. Behind the scenes, rspec marks Compares method arguments using the === operator.
Custom argument constraints can reduce repetition and make your expectations easier to understand.
Constraining how many times a method gets called
In addition to constraining a method arguments, you can also specify how many times it should be called.
client = instance_double('NasdaqClient')
expect(client).to receive(:current_price).thrice.and_raise(Timeout::Error)
stock_ticker = StockTicker.new(client)
100.times { stock_ticker.price('AAPL') }
Even though we’re calling stock_ticker.price many times, we expect the circuit breaker to stop hitting the network after the third simulated timeout error.
As you might guess from the name thrice, RSpec also provides once and twice modifiers. Since the English language doesn’t provide any multiplicative adverbs after 3, you’ll need to switch to the more verbose exactly(n).times
expect(client).to receive(:current_price).exactly(4).times
Ordering
Normally, RSpec doesn’t care what order you send messages to a test double:
expect(greeter).to receive(:hello).ordered
expect(greeter).to receive(:goodbye).ordered
# The following will fail:
greeter.goodbye
greeter.hello
Using ordered is a sign that your specs may be too coupled to one particular implementation/
You can use all of the types of constraints we’ve seen here—arguments, call counts, and ordering—together in one expectation:
expect(catalog).to receive(:search).
with(/term/).at_least(:twice).ordered
Summary of concepts covered in this chpater:
| Concept | Usage | Example |
|---|---|---|
| and_return | Configure test double to return specific values |
allow(double).to receive(:msg).and_return(value)allow(double).to receive(:msg).and_return(0.1, 0.2, 0.3)
|
| and_raise | Configure test double to raise exceptions |
allow(double).to receive(:msg).and_raise(AnException)allow(double).to receive(:msg).and_raise('error message')
|
| and_yield | Configure test double to yield values to blocks |
allow(extractor).to receive(:extract_urls) .and_yield('https://rspec.info/', 123)
|
| and_call_original | Fall back to original implementation (partial doubles) |
allow(File).to receive(:read).with('/etc/passwd').and_raise('NOPE')allow(File).to receive(:read).and_call_original
|
| and_wrap_original | Modify behavior of original method |
allow(CustomerService).to receive(:all).and_wrap_original do |orig| orig.call.take(10)end
|
| with | Constrain arguments that mock will accept |
expect(movie).to receive(:record_review).with('Great!')expect(cart).to receive(:add_product).with('Hoodie', anything)
|
| hash_including | Match hashes containing specific keys |
expect(box_office).to receive(:find_showtime) .with(hash_including(movie: 'Jaws'))
|
| Call count modifiers | Specify how many times method should be called |
expect(client).to receive(:current_price).thriceexpect(client).to receive(:price).exactly(4).times
|
| ordered | Enforce specific order of method calls |
expect(greeter).to receive(:hello).orderedexpect(greeter).to receive(:goodbye).ordered
|
Key Insight: Use expect vs allow wisely - expect changes behavior AND sets expectations, while allow only changes behavior. Custom blocks provide ultimate flexibility when built-in modifiers aren't enough. |
||
Here are some usefull articles i found about the topics we went over, and also i had chatGPT to provide me more details
https://stackoverflow.com/questions/28006913/rspec-allow-expect-vs-just-expect-and-return
https://martinfowler.com/articles/mocksArentStubs.html
https://chatgpt.com/share/68ad328f-1478-800a-9304-90c2de18939a
https://share.google/aimode/SFNEx3Z7x6YM1nYTJ
Part V — Chapter 15. Using test doubles effectively.
In this chapter we will see:
- the construction of an environment for each spec
- how to providde test doubles to the code we are testing
- what are the most common pitfalls and how to
- how to improve our code by applying this sign feedback from our test
Using test doubles effectively
Over the previous two chapters, we have tried out mocks, stubs, spies and null objects. We have learned which situation each is best for. We have also seen how to configure their behavior, and how to check that a double is called correctly. Now, we would like to talk about the trade-offs. Although we frequently use doubles in our tests, I will be the first to acknowledge that doing so incurs some risk.
- Code that passes the test but fails in production, because the test doubles don’t behave enough like a real.
- Brittle tests that fail after a refactoring, even though the new coat is working correctly
- Do-nothing tests that only end up checking your doubles
Construction or test environment
Details
- Effective testing with RSpec by Myron Marston and Ian Dees.
- Published: 2017
- Publisher: The Pragmatic Programmers